Real-time AI-curated news from 92,386+ articles across 50+ sources. Sentiment analysis, importance scoring, and key takeaways — updated every 15 minutes.
GeneralBearishCrypto Briefing · Jun 227/10
📰China's Hang Seng China Enterprises Index approaches bear market territory as weak domestic consumption data triggers investor concerns. The market shift reflects a broader pivot toward AI investments, signaling changing risk appetite and potential reallocation of capital from traditional sectors to technology.
AIBearishCrypto Briefing · Jun 227/10
🧠Anthropic has criticized US export controls on artificial intelligence models, warning that restrictive policies may force AI companies to relocate overseas. The criticism highlights growing tensions between national security interests and global innovation, with calls for European AI sovereignty increasing in response.
🏢 Anthropic
GeneralBullishCrypto Briefing · Jun 227/10
📰The U.S. and Iran have agreed on a roadmap to end military operations in Lebanon, potentially reducing regional tensions and creating conditions for lasting peace between Israel and Hezbollah. This diplomatic development could stabilize the Middle East and reduce geopolitical risk factors that have historically influenced cryptocurrency and commodity markets.
CryptoBullishBlockonomi · Jun 227/10
⛓️XRP exchange reserves have declined to seven-year lows of approximately 1.6 billion tokens while the asset stabilizes around $1.14, signaling reduced selling pressure from exchanges. Simultaneously, XRP-focused ETF products attracted $10.66 million in weekly inflows, with cumulative ETF accumulation reaching $1.45 billion, reflecting growing institutional interest despite declining exchange liquidity.
$XRP
CryptoBearishcrypto.news · Jun 227/10
⛓️The Wall Street Journal investigation reveals that Polymarket allegedly compensated social media creators to promote fabricated bets and fake winnings using replica versions of its platform, raising serious questions about market integrity and regulatory compliance in the prediction market space.
CryptoBullishThe Block · Jun 227/10
⛓️Bitget has launched Stock+, a new feature allowing users to purchase full and fractional US stocks directly using cryptocurrency through regulated brokers. This development bridges the crypto and traditional stock markets, enabling seamless asset diversification for crypto holders without requiring fiat currency conversion.
DeFiBearishBlockonomi · Jun 227/10
💎Altura has closed its USDT vault following $8.5M in withdrawals within 24 hours, driven by contagion fears stemming from the msUSD stablecoin collapse. The shutdown reflects broader trust concerns in the DeFi ecosystem after the failure of a related stablecoin project.
GeneralNeutralCrypto Briefing · Jun 227/10
📰Iran has reduced crude oil prices for Chinese buyers and increased shipment volumes following a recent peace agreement, potentially reshaping global oil market dynamics and intensifying competition for Asian energy supplies. This development could significantly impact oil-dependent economies and shift geopolitical energy relationships.
CryptoBearishCrypto Briefing · Jun 227/10
⛓️Q2 2026 recorded a record 70 cryptocurrency hacks resulting in $746 million in losses, marking a significant surge in the frequency and scale of security breaches. The proliferation of smaller, repeated attacks is expected to trigger heightened security protocols and regulatory oversight, with potential ripple effects across crypto market dynamics and investor confidence.
CryptoNeutralBlockonomi · Jun 227/10
⛓️Bitcoin surged past $64,000 following a positive conclusion to US-Iran diplomatic talks that included a lift on Hormuz blockade restrictions. However, the rally faces significant headwinds from record $6.35 billion in Bitcoin ETF outflows, suggesting institutional investors may be taking profits despite positive geopolitical developments.
$BTC
CryptoBullishThe Block · Jun 227/10
⛓️Toss Bank, a major South Korean fintech player, is partnering with Solana to develop a proof-of-concept for blockchain-based overseas remittances and stablecoin payments. This collaboration signals growing institutional adoption of blockchain infrastructure in Asia's payment systems and demonstrates Solana's expanding footprint in enterprise financial applications.
$SOL
GeneralBearishCrypto Briefing · Jun 227/10
📰A major explosion at QatarEnergy's Barzan facility in Qatar resulted in 54 injuries and 18 missing persons, underscoring critical vulnerabilities in global energy infrastructure. The incident highlights dual risks from both external threats and operational failures, with potential implications for energy market stability and geopolitical energy security.
GeneralNeutralCrypto Briefing · Jun 227/10
📰Mach Industries has secured $300M in Series C funding to advance autonomous military weapons programs across six initiatives. This funding round reflects growing investor confidence in defense-technology convergence and signals a significant shift toward autonomous systems in military applications.
CryptoBullishCrypto Briefing · Jun 227/10
⛓️Iran drew 0-0 with Belgium at the World Cup, reshaping Group G's knockout race dynamics. Concurrent with this match, cryptocurrency exchange Kraken announced its FIFA partnership debut, marking a significant milestone in crypto's mainstream sports sponsorship presence.
DeFiBearishcrypto.news · Jun 227/10
💎Taiko has issued an urgent warning for users to withdraw funds from its bridge following a compromise of its verification mechanism, with security firm Blockaid reporting over $1 million in losses from the exploit. The incident highlights critical vulnerabilities in cross-chain bridge infrastructure that continues to plague the DeFi ecosystem.
CryptoBullishCrypto Briefing · Jun 227/10
⛓️Japan's National Business Corporate Pension Fund plans to allocate 1% of its portfolio to cryptocurrency by fiscal 2026, marking a significant endorsement from a major institutional investor. This move reflects growing mainstream acceptance of digital assets as a legitimate component of diversified investment portfolios.
GeneralBullishCrypto Briefing · Jun 227/10
📰Iranian negotiators report progress in ongoing US peace talks, signaling potential de-escalation in Middle Eastern tensions. This diplomatic development could stabilize regional geopolitics and ease crude oil prices, creating ripple effects across global energy markets and cryptocurrency trading patterns tied to macro volatility.
GeneralBearishCrypto Briefing · Jun 227/10
📰A Supreme Court ruling has invalidated the International Emergency Economic Powers Act (IEEPA) as a basis for Trump's tariff authority, forcing the administration to pursue alternative legal frameworks and legislative support to implement trade policies. This development signals a potential shift in how executive tariff powers are exercised and may require Congress to codify tariff authorities or establish new mechanisms.
CryptoBullishThe Block · Jun 227/10
⛓️Japan's National Business Corporate Pension Fund is planning to allocate approximately 1% of its assets to cryptocurrency, marking a significant institutional adoption milestone in a major developed economy. This move signals growing acceptance of digital assets within traditional institutional investment frameworks.
GeneralBearishCrypto Briefing · Jun 22🔥 8/10
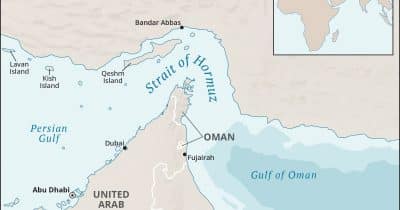
📰Iran's closure of the Strait of Hormuz has significantly disrupted global ship traffic, triggering volatility in oil markets and renewed attention to cryptocurrency's role in geopolitical and economic resilience. The incident underscores how regional tensions directly impact energy prices and financial markets, including digital assets.
GeneralBearishCrypto Briefing · Jun 22🔥 8/10
📰Escalating tensions in Iran are accelerating China's energy transition away from oil dependency, with significant implications for global crude markets and potential spillover effects into cryptocurrency and digital asset markets that correlate with macroeconomic energy shifts.
DeFiBearishThe Block · Jun 227/10
💎Ethereum Layer 2 solution Taiko halted block production after an exploit, prompting an urgent user withdrawal advisory. Security firm Blockaid identified a potential flaw in Taiko's bridge source-signal proof validation as the root cause, raising concerns about the protocol's cross-chain security infrastructure.
$ETH
CryptoBullishcrypto.news · Jun 227/10
⛓️Toss Bank, South Korea's digital banking platform, has signed a memorandum of understanding with the Solana Foundation to pilot Solana blockchain infrastructure for cross-border remittances and explore stablecoin integration in international payment flows. This partnership signals growing institutional adoption of layer-1 blockchain networks for payments infrastructure beyond traditional fintech solutions.
$SOL
GeneralBearishCrypto Briefing · Jun 22🔥 8/10
📰China has implemented new export controls targeting US rare earth firms, escalating trade tensions between the two nations. The measure threatens to disrupt critical industries reliant on rare earth materials, with potential ripple effects across global markets and supply chains.
GeneralBullishCrypto Briefing · Jun 227/10
📰Progress in US-Iran diplomatic negotiations is driving emerging-market stocks to record highs, as investors anticipate stabilized global energy markets and reduced inflationary pressures. The potential resolution could unlock significant investment opportunities across developing economies and support broader macroeconomic recovery.