Real-time AI-curated news from 92,396+ articles across 50+ sources. Sentiment analysis, importance scoring, and key takeaways — updated every 15 minutes.
CryptoBearishCrypto Briefing · Jun 22🔥 8/10
⛓️Escalating US-Iran tensions, including Trump's threats and potential Strait of Hormuz closure, are creating geopolitical uncertainty that ripples through cryptocurrency markets. The standoff underscores how crypto assets face increased regulatory scrutiny and volatility tied to international conflicts, affecting investor sentiment and market stability.
AIBullishCrypto Briefing · Jun 227/10
🧠South Korea's semiconductor exports surged 50% in June, driven by global AI demand, cementing the nation's critical role in the AI supply chain. While this growth demonstrates strong economic momentum, it also exposes South Korea to significant vulnerability from supply chain disruptions and geopolitical tensions.
AIBearishCrypto Briefing · Jun 227/10
🧠The US economy is driving over half of global credit impulse through aggressive AI spending, creating potential systemic risk if investment momentum slows. This concentration of credit expansion in a single economy and sector raises concerns about equity valuations and broader economic stability.
CryptoBearishCrypto Briefing · Jun 22🔥 8/10
⛓️The US government seized approximately $1 billion in Iranian cryptocurrency assets, creating significant obstacles for Iran's World Cup participation and highlighting how geopolitical sanctions extend into the digital asset space. This action demonstrates the intersection of sports diplomacy, international financial restrictions, and cryptocurrency regulation.
GeneralBearishCrypto Briefing · Jun 227/10
📰Gold prices declined as geopolitical tensions between the U.S. and Iran intensified during peace negotiations, with Trump issuing warnings that heightened market uncertainty. The movement reflects how traditional safe-haven assets respond to diplomatic volatility and shifting risk perceptions among investors.
CryptoBullishCrypto Briefing · Jun 227/10
⛓️The Blockchain Association is advocating for the House Ways and Means Committee to pass the Tax Clarity for Mining and Staking Act, legislation designed to simplify cryptocurrency taxation rules. The bill aims to reduce compliance complexity for miners and stakers while potentially encouraging greater institutional participation in blockchain technologies.
CryptoBullishCrypto Briefing · Jun 227/10
⛓️A Dutch court has accepted blockchain evidence in a data trafficking case, resulting in a two-year sentence for the defendant. This landmark decision strengthens the legal framework around blockchain technology and may encourage greater institutional adoption by clarifying how blockchain data can be used as admissible evidence in legal proceedings.
CryptoBullishCrypto Briefing · Jun 217/10
⛓️Avalanche's C-Chain has experienced a 6x surge in monthly transactions since June 2025, demonstrating strong adoption momentum for blockchain commerce. However, the network's fee reduction strategy raises questions about whether transaction growth can sustain revenue long-term as transaction volumes increase but per-transaction fees decline.
$AVAX
GeneralBearishFortune Crypto · Jun 21🔥 8/10
📰U.S.-Iran tensions escalated as Trump threatened military action against Iran if it closes the Strait of Hormuz, with rhetoric about taking control of the waterway and collecting tolls. The geopolitical rhetoric triggered broader market volatility, with Dow futures declining while oil prices surged due to supply disruption concerns affecting global energy markets.
AIBullishCrypto Briefing · Jun 217/10
🧠Anthropic's valuation has skyrocketed to approximately $965 billion from $4.1 billion in 2023, representing a roughly 235x increase that underscores massive investor confidence in artificial intelligence. The dramatic rise signals accelerating market momentum in the AI sector and strengthens Anthropic's positioning for a potential future IPO.
🏢 Anthropic
CryptoBullishCrypto Briefing · Jun 217/10
⛓️The Senate Finance Committee is advancing bipartisan cryptocurrency tax reform legislation that aims to clarify tax treatment of digital assets, reduce compliance complexity, and align U.S. regulatory standards with international approaches. This development signals growing legislative momentum toward establishing a more coherent crypto tax framework.
AIBullishOpenAI News · Jun 217/10
🧠Samsung Electronics has deployed ChatGPT Enterprise and OpenAI's Codex to its global workforce, representing one of OpenAI's largest enterprise AI implementations to date. This move signals mainstream corporate adoption of generative AI tools for productivity enhancement across a major multinational technology company.
🏢 OpenAI🧠 ChatGPT
CryptoBearishThe Block · Jun 217/10
⛓️Wall Street Journal investigation revealed that Polymarket paid influencers to create fake winning bet videos on dummy websites, with $1.9 million in fabricated bets across over 1,100 videos reviewed. This deceptive marketing practice undermines trust in prediction market platforms and raises serious questions about platform oversight and influencer accountability in the cryptocurrency space.
AIBearishCrypto Briefing · Jun 217/10
🧠AI data-center developers are increasingly building on-site gas plants to secure independent power supplies, bypassing grid infrastructure constraints. This trend threatens renewable energy adoption goals and locks in fossil fuel dependency, while raising environmental and community concerns.
GeneralBearishFortune Crypto · Jun 21🔥 8/10
📰U.S.-Iran diplomatic negotiations have stalled after President Trump issued threatening statements, prompting Iranian state media to declare talks had entered a "difficult phase" and recessed. The breakdown highlights escalating geopolitical tensions that could impact global markets, including energy prices and risk assets.
AIBullishCrypto Briefing · Jun 217/10
🧠Researchers from UC Berkeley, Nvidia, and Stanford have developed T-Rex, a framework enabling robots to respond to tactile sensations in real time. The technology enhances robotic adaptability in dynamic environments by processing physical contact feedback instantaneously, advancing automation capabilities across industrial and commercial applications.
🏢 Nvidia
CryptoBearishThe Block · Jun 217/10
⛓️A Chinese criminal network linked to fentanyl trafficking orchestrated a cryptocurrency fraud scheme from Japan, distributing counterfeit 'zksync.jp' tokens to deceive global crypto users and stealing over $1 million. The operation highlights how traditional organized crime syndicates are expanding into cryptocurrency fraud, blending illegal drug networks with digital asset scams.
CryptoBearishBlockonomi · Jun 217/10
⛓️A $36 million exploit of Humanity Protocol has escalated as stolen funds appear on KuCoin exchange after being converted to USDC. The attack stemmed from a phishing email that granted attackers admin access, enabling them to steal 141 million H tokens and mint additional assets.
CryptoBullishBlockonomi · Jun 217/10
⛓️A Japanese pension fund with ¥21.3 billion in assets has approved its first cryptocurrency allocation following a six-year research period, marking a significant institutional embrace of digital assets in Japan. The fund will reduce yen exposure while diversifying into crypto, gold, and global currencies during fiscal 2026, reflecting broader institutional appetite for digital assets.
GeneralNeutralCrypto Briefing · Jun 217/10
📰Israel has lifted war-related restrictions on northern border areas, signaling a potential de-escalation of regional tensions. While the move may stabilize markets in the short term, the underlying ceasefire remains fragile and presents ongoing geopolitical risks that could impact risk assets including cryptocurrency markets.
CryptoBullishBlockonomi · Jun 217/10
⛓️Major U.S. banks and the DTCC are accelerating tokenization initiatives for interbank settlement and securities trading, with tokenized stocks reaching $1.5 billion in value after 3,300% growth since 2024. The SEC's regulatory engagement signals institutional blockchain adoption is moving from experimental to mainstream, with a broader tokenized trading platform launching in October.
GeneralBearishCrypto Briefing · Jun 217/10
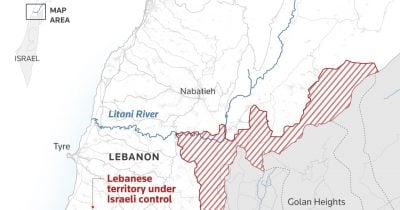
📰Israeli Prime Minister Netanyahu has declared Israel's intention to maintain a security zone in Lebanon indefinitely, a stance that could perpetuate regional instability and reduce prospects for peace agreements with Hezbollah. This hardline position signals prolonged geopolitical tension in the Middle East, which historically correlates with cryptocurrency market volatility and risk-asset repositioning.
CryptoBearishCoinDesk · Jun 217/10
⛓️CME Group filed a lawsuit against the CFTC on Thursday, challenging the agency's approval of Kalshi's perpetual futures product in the U.S. market. The suit raises fundamental questions about regulatory authority and product classification in cryptocurrency derivatives markets.
GeneralBearishFortune Crypto · Jun 217/10
📰AccuWeather has warned of conditions favoring a multi-year drought potentially resembling the Dust Bowl era, threatening crop yields and water supplies across rural America. This environmental crisis compounds existing economic pressures already affecting U.S. farms, with significant implications for agricultural productivity and food security.
GeneralBearishCrypto Briefing · Jun 21🔥 8/10
📰Senator Graham has indicated that the Trump administration is considering military seizure of the Strait of Hormuz if diplomatic negotiations fail, raising concerns about potential disruption to global oil markets. This geopolitical escalation could have significant implications for energy prices and broader financial markets, including cryptocurrency volatility tied to macroeconomic conditions.