GeneralBearishCrypto Briefing · Apr 28🔥 8/10
AI × Crypto News Feed
Real-time AI-curated news from 90,223+ articles across 50+ sources. Sentiment analysis, importance scoring, and key takeaways — updated every 15 minutes.
90223 articles

GeneralBearishCrypto Briefing · Apr 28🔥 8/10

CryptoBullishBitcoinist · Apr 28🔥 8/10

CryptoBullishCrypto Briefing · Apr 28🔥 8/10

GeneralBearishCrypto Briefing · Apr 28🔥 8/10

GeneralBearishFortune Crypto · Apr 27🔥 8/10

DeFiBearishGlassnode Insights · Apr 27🔥 8/10
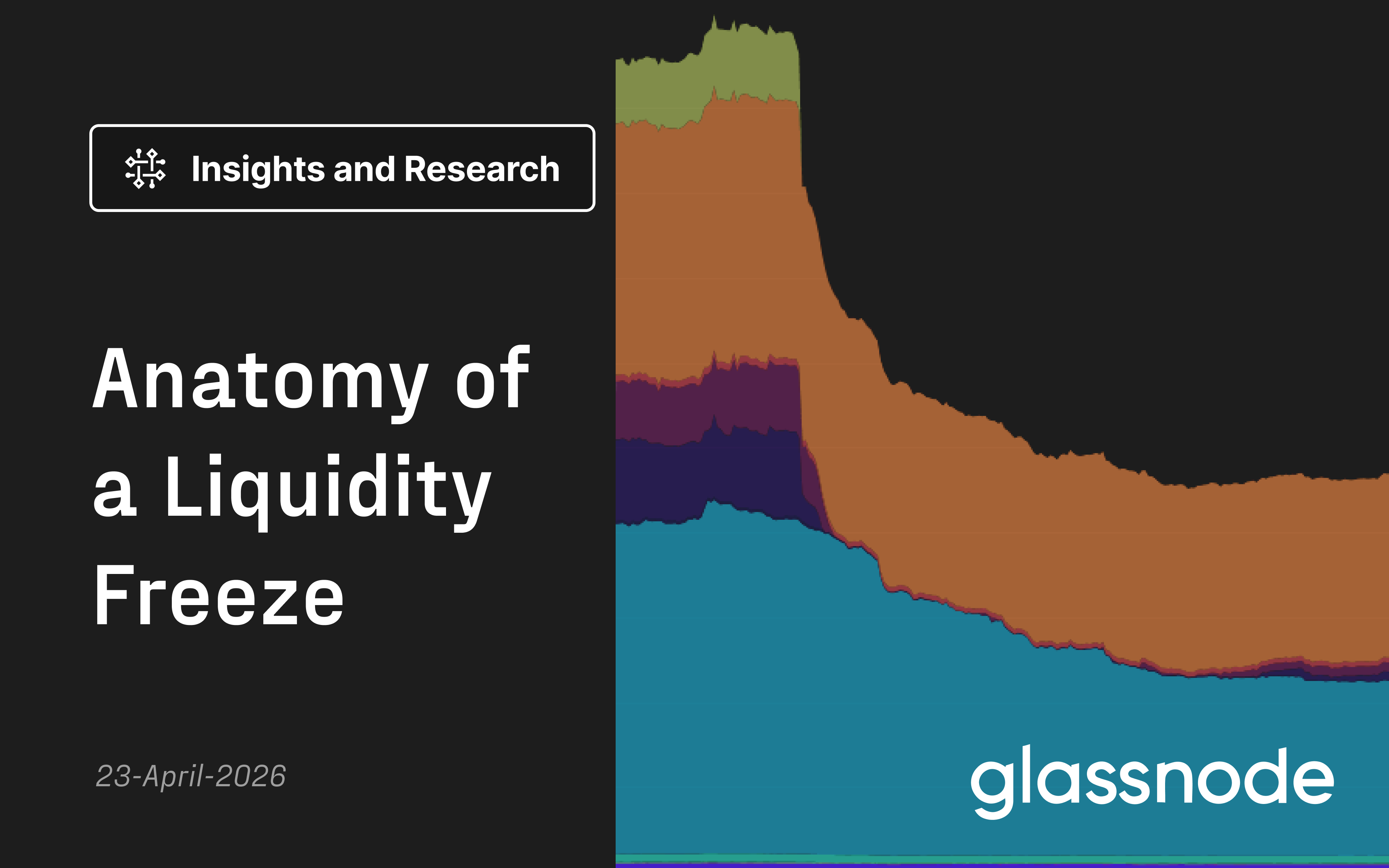
GeneralBearishCrypto Briefing · Apr 27🔥 8/10

GeneralBearishCrypto Briefing · Apr 27🔥 8/10

GeneralBearishCrypto Briefing · Apr 27🔥 8/10

GeneralBearishCrypto Briefing · Apr 27🔥 8/10

GeneralBearishCrypto Briefing · Apr 27🔥 8/10

GeneralBearishCrypto Briefing · Apr 27🔥 8/10

AIBearishBlockonomi · Apr 27🔥 8/10
GeneralBearishCrypto Briefing · Apr 27🔥 8/10

CryptoBearishBlockonomi · Apr 27🔥 8/10
GeneralBearishCrypto Briefing · Apr 27🔥 8/10

GeneralBearishCrypto Briefing · Apr 27🔥 8/10

CryptoBullishCrypto Briefing · Apr 27🔥 8/10

GeneralBearishCrypto Briefing · Apr 27🔥 8/10

GeneralBearishCrypto Briefing · Apr 27🔥 8/10

DeFiBearishCrypto Briefing · Apr 27🔥 8/10

GeneralBearishCrypto Briefing · Apr 26🔥 8/10

GeneralBearishCrypto Briefing · Apr 26🔥 8/10

GeneralBearishCrypto Briefing · Apr 26🔥 8/10
