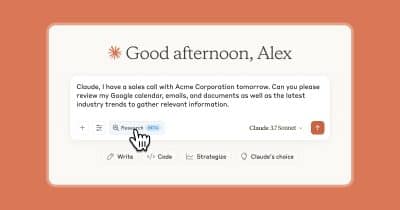
22,940 AI articles curated from 50+ sources with AI-powered sentiment analysis, importance scoring, and key takeaways.
AIBullishFortune Crypto · Jun 247/10
🧠Leading AI researchers, including the 'Godmother of AI,' are shifting focus from large language models and chatbots toward 'world models' that can perceive and react to physical environments in real-time. This paradigm shift represents a fundamental evolution in AI capabilities, moving beyond text-based understanding to embodied intelligence that interprets sensory data.
AIBearishWired – AI · Jun 247/10
🧠Google DeepMind invested $75 million in A24, a major indie film studio, prompting backlash from independent film supporters concerned about AI companies' expanding influence in Hollywood. The investment signals a strategic shift toward integrating AI capabilities into creative industries while raising questions about cultural independence and AI's role in content production.
🏢 Google
AIBullishCrypto Briefing · Jun 247/10
🧠Micron Technology reported $41.5 billion in quarterly revenue, exceeding Wall Street consensus estimates by approximately $6 billion. The exceptional performance reflects surging demand for memory chips driven by AI infrastructure expansion and broader technological advancement.
AIBullishCrypto Briefing · Jun 247/10
🧠SambaNova, an AI hardware company, is planning to raise $1 billion at a $10 billion valuation, representing a fivefold increase from its valuation just four months prior. This dramatic surge underscores robust investor appetite for specialized AI infrastructure and hardware solutions.
AIBearishCrypto Briefing · Jun 247/10
🧠Anthropic has reported that operators linked to Alibaba conducted mass distillation attacks targeting Claude's software engineering capabilities, attempting to extract and replicate the model's proprietary knowledge. The incident highlights critical vulnerabilities in AI systems and underscores the need for stronger security protocols and international regulatory frameworks to protect AI intellectual property.
🏢 Anthropic🧠 Claude
AIBullishCrypto Briefing · Jun 247/10
🧠Micron Technology has forecasted $50 billion in sales, exceeding analyst estimates, driven by surging demand for AI memory chips as the industry faces critical shortages. The company's strong guidance reflects how semiconductor supply constraints are reshaping the competitive landscape and accelerating adoption of advanced memory technologies essential for AI infrastructure.
AIBullishCrypto Briefing · Jun 247/10
🧠Notion has integrated Claude-powered AI agents into its platform, enabling automated data analysis, code generation, and task assignment capabilities. This move positions Notion as a competitive threat to established productivity platforms by combining advanced AI automation with collaborative workspace features.
🧠 Claude
AIBearishCrypto Briefing · Jun 247/10
🧠The General Services Administration (GSA) has proposed new AI regulations for government contractors that prioritize US-based companies and domestic AI solutions. These rules could reshape federal procurement practices and significantly impact global AI collaboration and competition in the government contracting space.
AIBullishCrypto Briefing · Jun 247/10
🧠Mirendil has secured a $200M seed round led by prominent investors a16z and Nvidia, underscoring significant institutional confidence in AI-driven scientific research. The funding round reflects a broader market shift toward companies leveraging artificial intelligence for breakthrough scientific discoveries and applications.
🏢 Nvidia
AIBullishCrypto Briefing · Jun 247/10
🧠Meta has secured multi-generation processor deals with Qualcomm, Broadcom, and AMD to power its XR and AI infrastructure. These long-term commitments strengthen Meta's competitive moat by ensuring reliable access to cutting-edge chips while raising barriers for competitors attempting to enter the spatial computing and AI markets.
AIBullishCrypto Briefing · Jun 247/10
🧠Databricks announced Omnigent and LTAP at its Data + AI Summit 2026, introducing innovations designed to disrupt traditional database architectures. These technologies aim to create a unified data ecosystem while establishing new standards for AI governance, potentially reshaping how enterprises manage data infrastructure.
AIBullishCrypto Briefing · Jun 247/10
🧠Qualcomm has secured Meta as a customer for its new AI data center processor, marking a significant strategic shift toward artificial intelligence infrastructure. This partnership demonstrates Qualcomm's commitment to long-term innovation in the competitive AI chip market, moving beyond its traditional mobile processor focus.
AIBearishDecrypt · Jun 247/10
🧠A physicist has published a formal critique challenging Microsoft's claims about successfully demonstrating the topological qubit technology underlying its Majorana 2 quantum chip. The critique raises questions about whether Microsoft has achieved the scientific breakthrough it announced, with potential implications for the company's quantum computing roadmap and investor confidence.
AIBearishCrypto Briefing · Jun 247/10
🧠Google has postponed the launch of Gemini 3.5 Pro to July 2026, a significant delay that may weaken its competitive position in the AI market. The postponement aligns Google's release timeline with competitors, potentially affecting market perception and the company's ability to capture early adoption advantages in advanced AI capabilities.
🧠 Gemini
AIBullishcrypto.news · Jun 247/10
🧠OpenAI has unveiled Jalapeño, its first custom-built AI chip, marking a strategic shift to reduce dependence on Nvidia and gain greater control over its AI infrastructure. This move reflects broader industry trends of major AI companies developing proprietary hardware to improve cost efficiency and operational independence.
🏢 OpenAI🏢 Nvidia
AIBearishCrypto Briefing · Jun 247/10
🧠Senator Elizabeth Warren is advocating for Congressional action to close regulatory loopholes that allow AI companies to avoid antitrust scrutiny through acqui-hire deals. This push targets transactions structured to sidestep merger reviews, potentially reshaping tech consolidation patterns by increasing regulatory friction on AI startup acquisitions.
AIBullishCrypto Briefing · Jun 247/10
🧠Google's Gemini 3.5 Flash has integrated computer use capabilities, enabling smaller teams to automate complex tasks through AI. This development democratizes advanced automation technology, potentially reshaping how organizations across various industries leverage artificial intelligence for operational efficiency.
🧠 Gemini
AINeutralThe Verge – AI · Jun 247/10
🧠In a competitive Democratic primary for New York's 12th Congressional District, Alex Bores narrowly lost to Micah Lasher despite a $27 million proxy war between AI companies Anthropic and OpenAI over his AI safety legislation. Bores, who authored the RAISE Act implementing guardrails on frontier AI companies, faced opposition from a $100 million super PAC funded by AI industry interests, highlighting growing tensions between AI safety advocates and major tech companies.
🏢 OpenAI🏢 Anthropic
AINeutralCrypto Briefing · Jun 247/10
🧠China's LineShine supercomputer has reclaimed the world's fastest supercomputer title, surpassing the U.S. El Capitan and ending a nine-year absence from the top spot. This development signals accelerating Chinese capabilities in high-performance computing and AI infrastructure, with potential implications for global technology competition and security frameworks.
AIBullishTechCrunch – AI · Jun 247/10
🧠Agility Robotics, an Oregon State University spinout founded in 2015, plans to go public through a SPAC merger valuing the company at $2.5 billion, with expected proceeds of $620 million. The move signals growing institutional confidence in the humanoid robotics sector and demonstrates how specialized robotics startups are transitioning from private funding rounds to public markets.
AIBullishBlockonomi · Jun 247/10
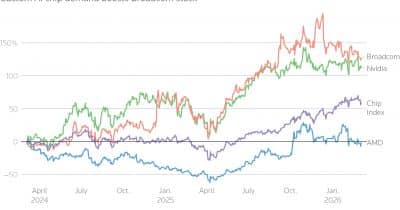
🧠Micron's earnings report and SK Hynix's announced $29 billion U.S. listing catalyzed a semiconductor sector rally, signaling investor confidence in chip stocks amid growing AI demand. The dual catalysts reflect strengthening fundamentals in memory chip markets as companies position for artificial intelligence infrastructure expansion.
AIBullishGoogle DeepMind Blog · Jun 247/10
🧠Google has introduced computer use capabilities to Gemini 3.5 Flash, enabling the AI model to interact with digital interfaces like a human user. This advancement represents a significant step toward more autonomous AI agents that can perform complex tasks across applications and websites.
🧠 Gemini
AIBullishCrypto Briefing · Jun 247/10
🧠Broadcom has announced a custom chip designed specifically for OpenAI, marking a significant challenge to Nvidia's dominant position in AI hardware. This development could diversify the AI chip market and potentially reduce computational costs for large language model operations.
🏢 OpenAI🏢 Nvidia
AIBearishCrypto Briefing · Jun 247/10
🧠A scientist has publicly questioned Microsoft's quantum computing claims published in Nature, challenging the company's progress in topological quantum computing. The skepticism underscores significant technical hurdles and industry-wide uncertainty about the commercial viability of Microsoft's quantum approach.
AINeutralFortune Crypto · Jun 247/10
🧠China's LineShine supercomputer has claimed the top position in the TOP500 ranking for the first time since 2017, displacing the U.S.-based El Capitan system. This shift represents a significant milestone in the global computational arms race and reflects China's advancing technological capabilities in high-performance computing infrastructure.