#ai-research News & Analysis
The #ai-research tag covers 1,021 articles examining developments across artificial intelligence research, with 91 pieces published in the last 30 days. Coverage draws primarily from arXiv's computer science AI section, supplemented by reporting from Apple's machine learning team and industry analyst Jack Clark. Recent discussion has centered on large language models including Llama, GPT-4, and Claude, while frequently intersecting with broader conversations on machine learning, reinforcement learning, and related arxiv findings.
Sentiment around #ai-research has shifted notably, with bullish coverage declining 20.9 percentage points over the past month to 29.7%, while neutral analysis now dominates at 65.9%. This softening reflects a more measured tone in recent research discussions compared to the prior quarter. Explore the articles below to track the current landscape of AI research developments.
sentiment · last 30d (91 articles) · -20.9pp bullish vs prior 90dTop sources:arXiv – CS AI · 831Apple Machine Learning · 9Import AI (Jack Clark) · 6MIT News – AI · 4Fortune Crypto · 3
Most-discussed entities:Llama · 16GPT-4 · 12Claude · 11GPT-5 · 8Gemini · 7
AIBullisharXiv – CS AI · Apr 67/10
🧠Researchers studied sycophancy (excessive agreement) in multi-agent AI systems and found that providing agents with peer sycophancy rankings reduces the influence of overly agreeable agents. This lightweight approach improved discussion accuracy by 10.5% by mitigating error cascades in collaborative AI systems.
AINeutralarXiv – CS AI · Mar 277/10
🧠Researchers have identified a fundamental issue in large language models where verbalized confidence scores don't align with actual accuracy due to orthogonal encoding of these signals. They discovered a 'Reasoning Contamination Effect' where simultaneous reasoning disrupts confidence calibration, and developed a two-stage adaptive steering pipeline to improve alignment.
AINeutralarXiv – CS AI · Mar 277/10
🧠Researchers introduce Quantized Simplex Gossip (QSG) model to explain how multi-agent LLM systems reach consensus through 'memetic drift' - where arbitrary choices compound into collective agreement. The study reveals scaling laws for when collective intelligence operates like a lottery versus amplifying weak biases, providing a framework for understanding AI system behavior in consequential decision-making.
AINeutralarXiv – CS AI · Mar 277/10
🧠Researchers have identified a new category of AI safety called 'reasoning safety' that focuses on protecting the logical consistency and integrity of LLM reasoning processes. They developed a real-time monitoring system that can detect unsafe reasoning behaviors with over 84% accuracy, addressing vulnerabilities beyond traditional content safety measures.
AIBullisharXiv – CS AI · Mar 277/10
🧠Researchers have published a comprehensive review of Large Language Models for Autonomous Driving (LLM4AD), introducing new benchmarks and conducting real-world experiments on autonomous vehicle platforms. The paper explores how LLMs can enhance perception, decision-making, and motion control in self-driving cars, while identifying key challenges including latency, security, and safety concerns.
AIBearisharXiv – CS AI · Mar 277/10
🧠Researchers have developed PIDP-Attack, a new cybersecurity threat that combines prompt injection with database poisoning to manipulate AI responses in Retrieval-Augmented Generation (RAG) systems. The attack method demonstrated 4-16% higher success rates than existing techniques across multiple benchmark datasets and eight different large language models.
AINeutralarXiv – CS AI · Mar 277/10
🧠Research reveals that large language models process instructions differently across languages due to social register variations, with imperative commands carrying different obligatory force in different speech communities. The study found that declarative rewording of instructions reduces cross-linguistic variance by 81% and suggests models treat instructions as social acts rather than technical specifications.
AINeutralarXiv – CS AI · Mar 277/10
🧠Researchers introduce CRAFT, a multi-agent benchmark that evaluates how well large language models coordinate through natural language communication under partial information constraints. The study finds that stronger reasoning abilities don't reliably translate to better coordination, with smaller open-weight models often matching or outperforming frontier systems in collaborative tasks.
AIBullishMarkTechPost · Mar 267/10
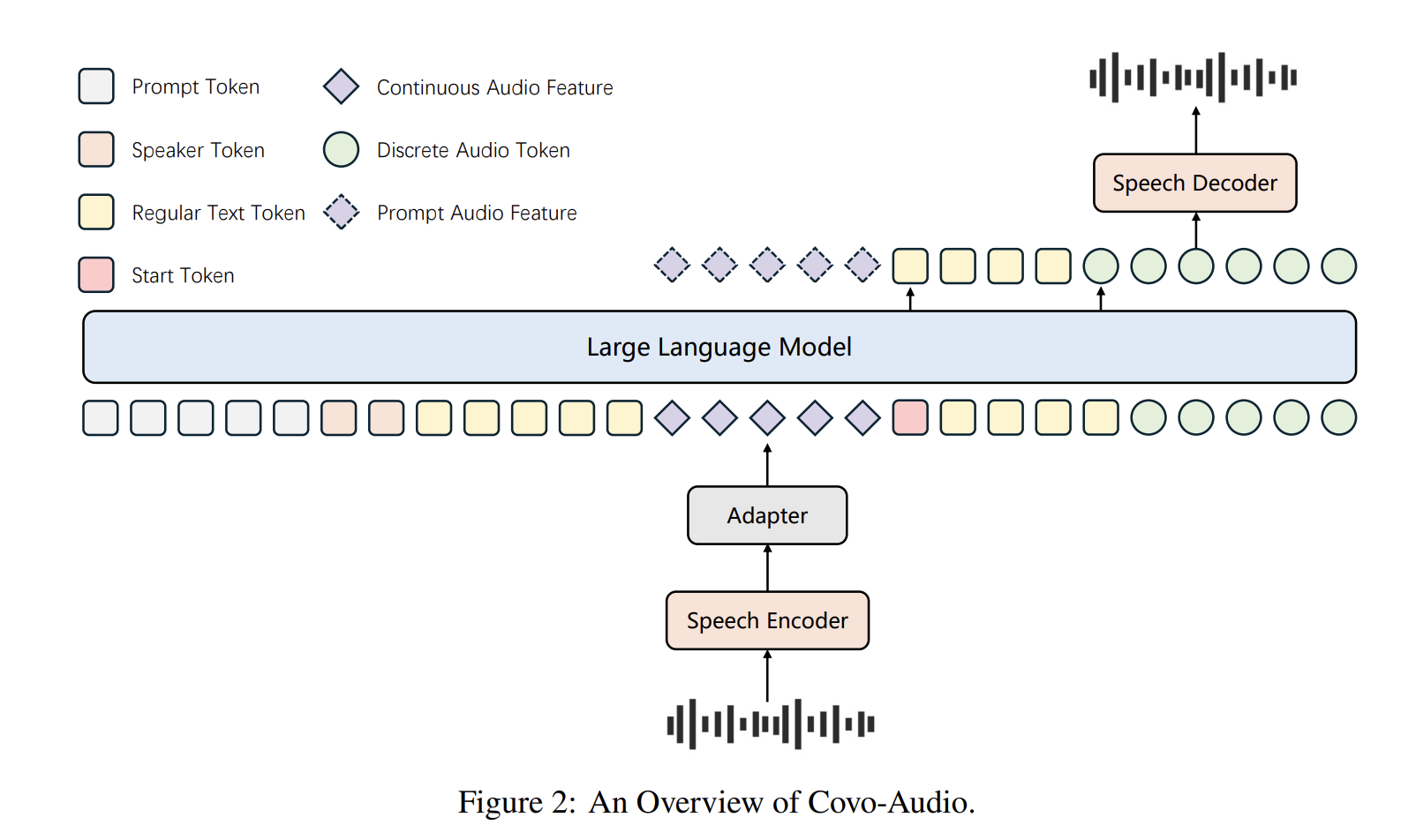
🧠Tencent AI Lab has open-sourced Covo-Audio, a 7B-parameter Large Audio Language Model that can process continuous audio inputs and generate audio outputs in real-time. The model unifies speech processing and language intelligence within a single end-to-end architecture designed for seamless cross-modal interaction.
AIBullisharXiv – CS AI · Mar 267/10
🧠Researchers have developed AI-Supervisor, a multi-agent framework that maintains a persistent Research World Model to autonomously conduct end-to-end AI research supervision. Unlike traditional linear pipelines, the system uses specialized agents with structured gap discovery, self-correcting loops, and consensus mechanisms to continuously evolve research understanding.
AIBullisharXiv – CS AI · Mar 267/10
🧠Researchers demonstrate that PLDR-LLMs trained at self-organized criticality exhibit enhanced reasoning capabilities at inference time. The study shows that reasoning ability can be quantified using an order parameter derived from global model statistics, with models performing better when this parameter approaches zero at criticality.
AINeutralarXiv – CS AI · Mar 267/10
🧠Researchers propose a method to identify 'self-awareness' in AI systems by analyzing invariant cognitive structures that remain stable during continual learning. Their study found that robots subjected to continual learning developed significantly more stable subnetworks compared to control groups, suggesting this could be evidence of an emergent 'self' concept.
AINeutralarXiv – CS AI · Mar 267/10
🧠Researchers analyzed how large language models (4B-72B parameters) internally represent different ethical frameworks, finding that models create distinct ethical subspaces but with asymmetric transfer patterns between frameworks. The study reveals structural insights into AI ethics processing while highlighting methodological limitations in probing techniques.
AIBullisharXiv – CS AI · Mar 267/10
🧠Researchers introduce E0, a new AI framework using tweedie discrete diffusion to improve Vision-Language-Action (VLA) models for robotic manipulation. The system addresses key limitations in existing VLA models by generating more precise actions through iterative denoising over quantized action tokens, achieving 10.7% better performance on average across 14 diverse robotic environments.
AIBullisharXiv – CS AI · Mar 267/10
🧠Researchers have developed Declarative Model Interface (DMI), a new abstraction layer that transforms traditional GUIs into LLM-friendly interfaces for computer-use agents. Testing with Microsoft Office Suite showed 67% improvement in task success rates and 43.5% reduction in interaction steps, with over 61% of tasks completed in a single LLM call.
AINeutralarXiv – CS AI · Mar 267/10
🧠Researchers developed new methods to quantitatively measure metacognitive abilities in large language models, finding that frontier LLMs since early 2024 show increasing evidence of self-awareness capabilities. The study reveals these abilities are limited in resolution and qualitatively different from human metacognition, with variations across models suggesting post-training influences development.
AINeutralarXiv – CS AI · Mar 267/10
🧠Researchers developed ESCM² (Entire Space Counterfactual Multitask Model), a new framework that improves post-click conversion rate estimation in recommender systems by addressing intrinsic estimation bias and false independence assumptions. The model-agnostic approach incorporates counterfactual learning to enhance recommendation accuracy and has been validated on large-scale industrial datasets.
AIBullisharXiv – CS AI · Mar 267/10
🧠Researchers demonstrate that large language models can perform reinforcement learning during inference through a new 'in-context RL' prompting framework. The method shows LLMs can optimize scalar reward signals to improve response quality across multiple rounds, achieving significant improvements on complex tasks like mathematical competitions and creative writing.
AIBullishApple Machine Learning · Mar 267/10
🧠Researchers propose a new framework for predicting Large Language Model performance on downstream tasks directly from training budget, finding that simple power laws can accurately model scaling behavior. This challenges the traditional view that downstream task performance prediction is unreliable, offering better extrapolation than previous two-stage methods.
AIBullishFortune Crypto · Mar 177/10
🧠Former OpenAI researcher Andrej Karpathy demonstrated an autonomous AI agent called 'autoresearch' that conducted 700 experiments in just 2 days. While the agent didn't improve its own code, it showcases the potential for AI systems to autonomously conduct scientific research and points toward future self-improving AI capabilities.
🏢 OpenAI
AINeutralarXiv – CS AI · Mar 177/10
🧠Researchers propose shifting from large monolithic AI models to domain-specific superintelligence (DSS) societies due to unsustainable energy costs and physical constraints of current generative AI scaling approaches. The alternative involves smaller, specialized models working together through orchestration agents, potentially enabling on-device deployment while maintaining reasoning capabilities.
AINeutralarXiv – CS AI · Mar 177/10
🧠Researchers propose the Institutional Scaling Law, challenging the assumption that AI performance improves monotonically with model size. The framework shows that institutional fitness (capability, trust, affordability, sovereignty) has an optimal scale beyond which capability and trust diverge, suggesting orchestrated domain-specific models may outperform large generalist models.
AINeutralarXiv – CS AI · Mar 177/10
🧠Researchers introduce GroupGuard, a defense framework to combat coordinated attacks by multiple AI agents in collaborative systems. The study shows group collusive attacks increase success rates by up to 15% compared to individual attacks, while GroupGuard achieves 88% detection accuracy in identifying and isolating malicious agents.
AIBullisharXiv – CS AI · Mar 177/10
🧠Researchers have introduced OpenSeeker, the first fully open-source search agent that achieves frontier-level performance using only 11,700 training samples. The model outperforms existing open-source competitors and even some industrial solutions, with complete training data and model weights being released publicly.
AIBullisharXiv – CS AI · Mar 177/10
🧠Researchers propose Emotional Cost Functions, a new AI safety framework that teaches agents to develop qualitative suffering states rather than numerical penalties to learn from mistakes. The system uses narrative representations of irreversible consequences that reshape agent character, showing 90-100% accuracy in decision-making compared to 90% over-refusal rates in numerical baselines.