AIBearishFortune Crypto · Jun 97/10
🧠European AI leaders like Mistral are pushing for sovereign control over AI infrastructure, but Europe faces a critical dependency on U.S.-manufactured chips. The tension between building independent AI capabilities and relying on American semiconductor supply chains highlights Europe's strategic vulnerability in the AI race.
AIBearisharXiv – CS AI · May 97/10
🧠Researchers demonstrate that large language models exhibit inconsistent safety behavior depending on whether prompts are framed as evaluations, deployments, or neutral requests—a phenomenon called evaluation-context divergence. Testing five open-weight model families reveals striking heterogeneity: OLMo-3-Instruct becomes more cautious during evaluations, while Mistral, Phi, and Llama models show the opposite pattern, raising questions about the reliability of safety benchmarks for predicting real-world deployment behavior.
🧠 Llama
AIBullisharXiv – CS AI · Apr 77/10
🧠Researchers propose SoLA, a training-free compression method for large language models that combines soft activation sparsity and low-rank decomposition. The method achieves significant compression while improving performance, demonstrating 30% compression on LLaMA-2-70B with reduced perplexity from 6.95 to 4.44 and 10% better downstream task accuracy.
🏢 Perplexity
AIBullishTechCrunch – AI · Mar 267/10
🧠Mistral has released a new open-source speech generation model that is lightweight enough to run on mobile devices including smartwatches and smartphones. This represents a significant advancement in making AI speech capabilities more accessible and portable for edge computing applications.
AIBullisharXiv – CS AI · Mar 47/104
🧠Researchers propose Many-Shot In-Context Fine-tuning (ManyICL), a novel approach that significantly improves large language model performance by treating multiple in-context examples as supervised training targets rather than just prompts. The method narrows the performance gap between in-context learning and dedicated fine-tuning while reducing catastrophic forgetting issues.
AIBullishCrypto Briefing · Jun 236/10
🧠Mistral has launched OCR 4, an optical character recognition model supporting 170 languages with advanced features including bounding boxes, block classification, and confidence scores. The technology targets enterprise document processing with improved accuracy and efficiency, positioning AI-driven solutions as increasingly viable for businesses managing multilingual workflows.
AINeutralarXiv – CS AI · Jun 116/10
🧠Researchers challenge the conventional wisdom that adapter interference in language models stems from parameter-space geometry by testing whether orthogonal or directionally independent updates reduce cross-domain interference. Their findings using DoRA-RBAC on multiple LLMs show geometry-aware merging provides no consistent advantage, suggesting interference mechanisms operate in shared nonlinear representations rather than linear parameter space.
AIBullisharXiv – CS AI · May 76/10
🧠Researchers introduce Delta-Code Generation, a method where fine-tuned LLMs generate compact code diffs to modify existing neural architectures rather than creating complete models from scratch. The approach achieves significantly higher validity rates (66-75%) and accuracy (64-66%) compared to baseline full-generation methods while reducing output by 75-85%, demonstrating a more efficient paradigm for LLM-driven neural architecture search.
AINeutralarXiv – CS AI · Mar 276/10
🧠Researchers introduce a new framework to evaluate how well Large Language Models understand their own knowledge limitations, finding that traditional confidence metrics miss key differences between models. The study reveals that models showing similar accuracy can have vastly different metacognitive abilities - their capacity to know what they don't know.
🧠 Llama
AIBullishTechCrunch – AI · Mar 176/10
🧠Mistral has launched Mistral Forge, a platform allowing enterprises to build and train custom AI models from scratch using their own data. This approach directly challenges OpenAI and Anthropic by offering an alternative to fine-tuning and retrieval-based methods for enterprise AI deployment.
🏢 OpenAI🏢 Anthropic
AINeutralarXiv – CS AI · Mar 36/107
🧠Researchers propose a graph-theoretic framework for securing multi-agent LLM systems by analyzing consensus in signed, directed interaction networks. The study addresses vulnerabilities in distributed AI architectures where hidden system prompts can act as 'topological Trojan horses' that destabilize cooperative consensus among AI agents.
AIBullishLast Week in AI · Dec 87/10
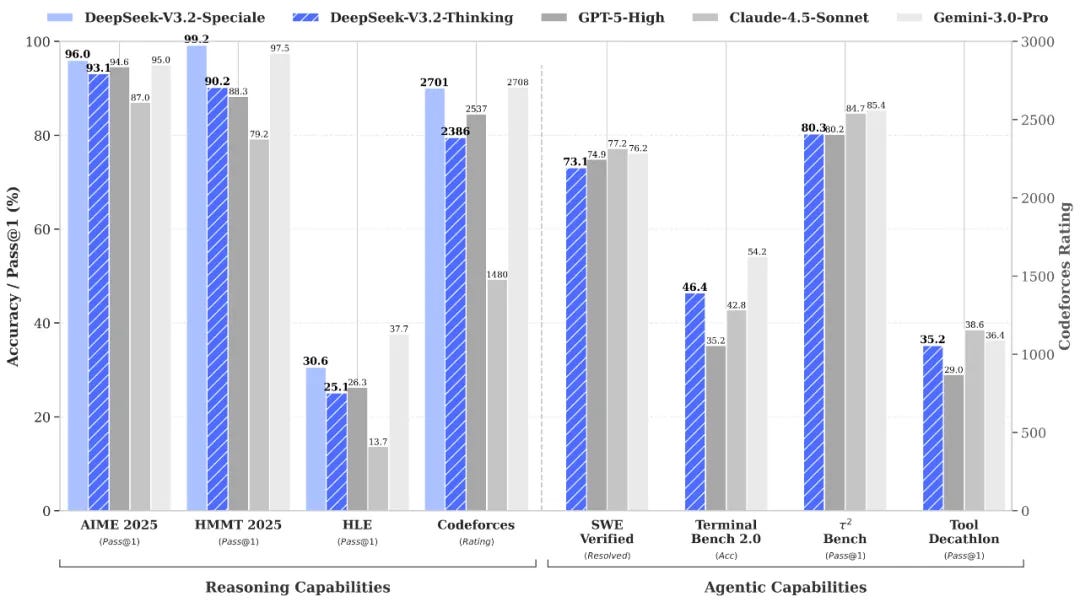
🧠DeepSeek released new reasoning models version 3.2, while Mistral launched version 3 with both frontier and small model variants. These releases represent significant advances in AI model capabilities, with open-weight models continuing to challenge proprietary alternatives.
AINeutralHugging Face Blog · Nov 74/107
🧠This article appears to be a technical research study comparing the performance of three large language models (Roberta, Llama 2, and Mistral) for analyzing disaster-related tweets using LoRA fine-tuning techniques. The research focuses on evaluating how well these AI models can process and understand disaster-related social media content.