AIBullisharXiv – CS AI · Jun 27/10
🧠FastSLM introduces a Hierarchical Temporal Abstractor (HTA) that compresses long-form speech into just 1.67 tokens per second—a 97% reduction—while maintaining competitive performance on speech understanding benchmarks. This architecture solves a critical scaling bottleneck for multimodal AI models by preserving acoustic detail despite extreme compression, enabling efficient deployment of speech-capable language models.
AIBullishMarkTechPost · Mar 267/10
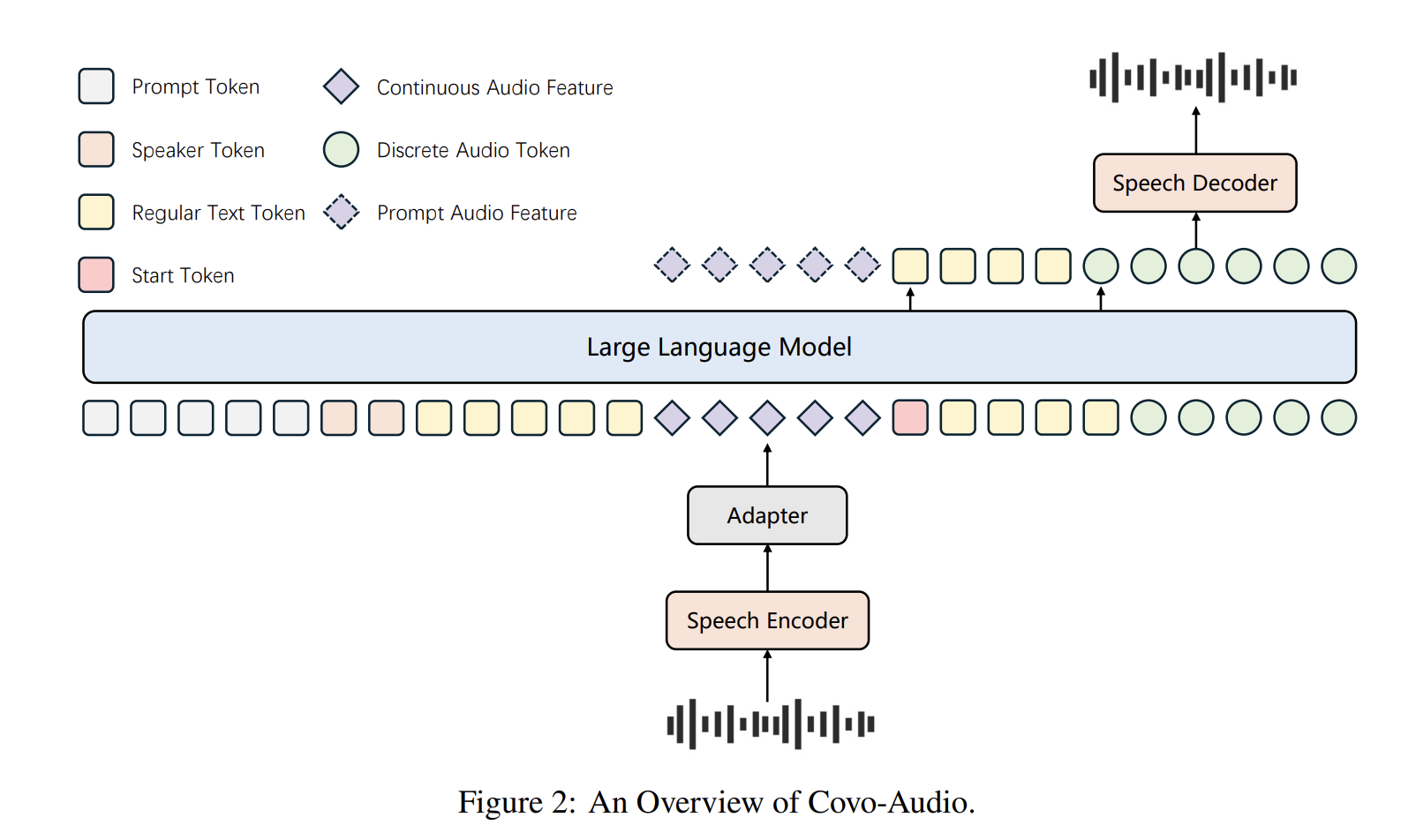
🧠Tencent AI Lab has open-sourced Covo-Audio, a 7B-parameter Large Audio Language Model that can process continuous audio inputs and generate audio outputs in real-time. The model unifies speech processing and language intelligence within a single end-to-end architecture designed for seamless cross-modal interaction.
AINeutralarXiv – CS AI · Mar 177/10
🧠Researchers demonstrate that current audio deepfake detection systems incorrectly classify legitimate speech processing technologies like voice conversion and restoration as fake audio. A new multi-class detection approach shows improved accuracy by distinguishing between authentic speech, benign modifications, and actual spoofing attempts.
AINeutralarXiv – CS AI · Jun 255/10
🧠Researchers analyzed how a Wav2Vec 2.0-based machine learning model interprets acoustic features in speech from oral and oropharyngeal cancer patients. Using canonical correlation analysis, they found the model's learned representations most strongly correlate with spectral and prosodic features, providing practical insights for improving pathological speech assessment systems.
AINeutralarXiv – CS AI · Jun 196/10
🧠Researchers introduce RIVET, a training framework that uses idempotency constraints to improve voice attribute editing models' robustness to noisy or inconsistent labels in large-scale speech datasets. By enforcing the property that repeated applications produce identical results, the method acts as an implicit regularizer that reduces sensitivity to mislabeled training data while preserving speaker identity.
AINeutralarXiv – CS AI · Jun 105/10
🧠This academic research applies AI-driven speech processing to analyze team-teaching dynamics in university classrooms across 36 sessions. The study reveals that experienced teachers, undergraduate instruction, and collaborative learning tasks correlate with greater loudness variation, suggesting strategic vocal modulation to enhance engagement and highlight key information.
AIBullisharXiv – CS AI · Jun 86/10
🧠Researchers propose SpectCount, a synthetic data fine-tuning method that improves large audio language models (LALMs) by generating on-the-fly audio signals to address spectrotemporal perceptual weaknesses. The approach bypasses the bottleneck of scarce annotated audio data and demonstrates performance gains across diverse auditory benchmarks without requiring real-world audio or pretrained generative models.
AINeutralarXiv – CS AI · May 296/10
🧠This survey comprehensively reviews end-to-end neural architectures for multi-speaker automatic speech recognition on monaural audio, analyzing SIMO vs. SISO paradigms, recent algorithmic improvements, and extensions to long-form speech. The work addresses a critical gap in literature by systematizing recent advances in a field transitioning from cascade to unified E2E systems that better handle overlapping speech and speaker attribution.
AINeutralarXiv – CS AI · May 286/10
🧠Researchers challenge the widespread practice of using global token perplexity to evaluate generative spoken language models, arguing this metric fails to account for fundamental differences between speech and text modalities. The study proposes alternative likelihood- and generative-based evaluation methods that correlate more strongly with human perception, revealing that performance gaps between leading models and human baselines are smaller than previously believed.
🏢 Perplexity
AIBullisharXiv – CS AI · May 276/10
🧠Researchers have released ParsVoice, a 2,200-hour Persian speech dataset with 1.36 million aligned segments from 1,815 speakers, making it 25 times larger than previous Persian TTS resources. The dataset was constructed using an automated pipeline combining ASR, fine-tuned language models, and quality assessment, and validation shows the corpus enables multi-speaker text-to-speech systems competitive with existing solutions.
🏢 Hugging Face
AINeutralarXiv – CS AI · Apr 206/10
🧠Researchers introduce DASB, a comprehensive benchmark framework for evaluating discrete audio tokens across speech, audio, and music domains. The study reveals that discrete representations lag behind continuous features and require significant tuning, with semantic tokens outperforming acoustic ones, establishing standardized evaluation protocols for multimodal AI systems.
AINeutralarXiv – CS AI · Apr 206/10
🧠Researchers formalize the one-sided conversation problem (1SC), where only one participant's dialogue can be recorded—common in telemedicine, call centers, and smart glasses. The study evaluates methods to reconstruct missing speaker turns and generate summaries from incomplete transcripts, finding that smaller models require finetuning while larger models show promise with prompting techniques.
AINeutralarXiv – CS AI · Apr 136/10
🧠Researchers demonstrate that applying Bayesian inference to Spiking Neural Networks (SNNs) for speech processing smooths the irregular loss landscape caused by threshold-based spike generation. Testing on speech datasets shows improved performance metrics and more regular predictive landscapes compared to deterministic approaches.
AINeutralarXiv – CS AI · Mar 176/10
🧠Researchers introduce a structural taxonomy and unified evaluation framework for Audio Large Language Models (ALLMs) to assess fairness, safety, and security. The study reveals systematic differences in how ALLMs handle audio versus text inputs, with FSS behavior closely tied to acoustic information integration methods.
AIBullisharXiv – CS AI · Mar 176/10
🧠Researchers developed training-free model steering techniques to improve reasoning in large audio-language models (LALMs) through chain-of-thought prompting. The approach achieved up to 4.4% accuracy gains and demonstrated cross-modal transfer where text-derived steering vectors can effectively guide speech-based reasoning.
AIBullisharXiv – CS AI · Mar 116/10
🧠Facebook Research introduces the Latent Speech-Text Transformer (LST), which aggregates speech tokens into higher-level patches to improve computational efficiency and cross-modal alignment. The model achieves up to +6.5% absolute gain on speech HellaSwag benchmarks while maintaining text performance and reducing inference costs for ASR and TTS tasks.
AINeutralarXiv – CS AI · Mar 36/105
🧠Researchers introduced Spoof-SUPERB, a new benchmark for evaluating self-supervised learning models' ability to detect audio deepfakes. The study tested 20 SSL models and found that large-scale discriminative models like XLS-R and WavLM Large consistently outperformed others, especially under acoustic degradations.
AIBullisharXiv – CS AI · Feb 275/103
🧠Researchers developed Lipi-Ghor-882, an 882-hour Bengali speech dataset, and demonstrated that targeted fine-tuning with synthetic acoustic degradation significantly improves automatic speech recognition for long-form Bengali audio. Their dual pipeline achieved a 0.019 Real-Time Factor, establishing new benchmarks for low-resource speech processing.
AIBullishHugging Face Blog · Apr 96/105
🧠Hugging Face and Cloudflare have partnered to launch FastRTC, a solution designed to enable seamless real-time speech and video processing. This collaboration combines Hugging Face's AI models with Cloudflare's edge computing infrastructure to reduce latency in real-time communications.
AINeutralarXiv – CS AI · Apr 145/10
🧠Researchers developed a lightweight machine learning system that detects voicemail greetings versus live human answers in real-time telephony audio with 96.1% accuracy using only temporal speech activity patterns. The system processes calls in 46ms on standard CPUs and has been validated across 77,000 production calls, achieving practical false positive and negative rates suitable for AI calling applications.
AINeutralarXiv – CS AI · Mar 124/10
🧠Researchers propose AMB-DSGDN, a new AI system for multimodal emotion recognition that uses adaptive modality balancing and differential graph attention mechanisms. The system addresses limitations in existing approaches by filtering noise and preventing dominant modalities from overwhelming the fusion process in text, speech, and visual data.
AINeutralarXiv – CS AI · Mar 44/104
🧠Researchers have developed TVF (Time-Varying Filtering), a lightweight 1 million parameter speech enhancement model that combines digital signal processing with deep learning for real-time speech denoising. The model uses a neural network to predict coefficients for a 35-band IIR filter cascade, offering interpretable processing while adapting dynamically to changing noise conditions.
AINeutralarXiv – CS AI · Mar 34/103
🧠CodecFlow is a new neural codec-based framework for speech bandwidth extension that efficiently reconstructs high-quality audio in compact latent space. The system uses conditional flow matching and residual vector quantization to improve speech clarity by restoring high-frequency content from low-bandwidth audio.
AINeutralarXiv – CS AI · Feb 273/107
🧠This linguistic research study analyzes how Vietnamese learners of Mandarin Chinese acquire prosodic patterns, finding that advanced learners achieve native-like quantity in speech boundaries but develop inverted structural mapping patterns. The study reveals a trade-off between maintaining fluent output and achieving accurate prosodic structure in second language acquisition.