MiniMax teases M3 model with 15.6x faster decoding speed boost
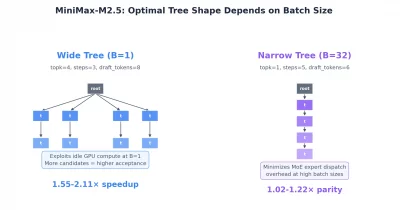
MiniMax has announced its M3 model featuring a 15.6x faster decoding speed compared to previous versions, potentially reducing latency and operational costs for decentralized AI applications. This advancement could enhance scalability and efficiency across AI infrastructure, making decentralized AI systems more practical and cost-effective for broader adoption.
MiniMax's M3 model represents a significant technical advancement in AI inference optimization, directly addressing one of the most pressing challenges in deploying large language models at scale. The 15.6x improvement in decoding speed substantially reduces the time required to generate text outputs, which has major implications for both centralized and decentralized AI systems where inference latency directly correlates with user experience and operational expenses.
The decoding speed bottleneck has historically limited the practical applications of large language models, particularly in real-time use cases and cost-sensitive environments. By dramatically improving throughput, MiniMax enables more efficient resource utilization, lower computational costs per inference, and faster response times. This becomes especially critical for decentralized AI networks where computational resources are distributed and efficiency gains directly translate to improved economics for node operators and service providers.
For the broader AI crypto ecosystem, this development strengthens the viability of decentralized AI infrastructure as a competitive alternative to centralized cloud providers. Improved efficiency metrics reduce barriers to entry for decentralized AI platforms and make token economics more favorable for networks that reward computation. Projects building on decentralized inference networks could achieve cost parity or advantages over traditional cloud solutions, potentially accelerating ecosystem growth.
Market participants should monitor whether MiniMax commercializes this technology through partnerships with major AI infrastructure projects or launches its own decentralized platform. The competitive landscape for AI inference optimization remains intense, and technical breakthroughs like this often drive rapid iteration across the industry, potentially triggering similar improvements from competitors.
- →MiniMax's M3 model achieves 15.6x faster decoding speed, directly addressing latency and cost challenges in AI inference.
- →Improved decoding efficiency reduces operational costs and enhances user experience for decentralized AI applications.
- →The advancement strengthens the economic viability of decentralized AI infrastructure competing against centralized cloud providers.
- →Faster inference enables broader real-time use cases previously impractical due to latency constraints.
- →This technical milestone could accelerate adoption of decentralized AI networks if commercialized effectively.