AIBullisharXiv – CS AI · Jun 97/10
🧠Researchers introduce Audio-FLAN, a large-scale instruction-tuning dataset with over 100 million instances covering 80 diverse tasks across speech, music, and sound domains. This dataset addresses a critical gap in unified audio-language models by enabling both audio understanding and generation tasks, advancing the integration of audio capabilities into large language models.
🏢 Hugging Face
AIBearisharXiv – CS AI · May 287/10
🧠Research reveals that voice cloning technology doesn't faithfully replicate voices but instead applies systematic style transfer, making cloned voices sound more authoritative and trustworthy than originals. The findings expose significant limitations in current voice cloning models, including homogenization of speaker characteristics and potential risks related to human behavioral manipulation through altered voice perception.
AIBullisharXiv – CS AI · Apr 147/10
🧠Researchers introduce Audio Flamingo Next (AF-Next), an advanced open-source audio-language model that processes speech, sound, and music with support for inputs up to 30 minutes. The model incorporates a new temporal reasoning approach and demonstrates competitive or superior performance compared to larger proprietary alternatives across 20 benchmarks.
AINeutralArs Technica – AI · Mar 267/10
🧠Google is launching Gemini 3.1 Flash Live, a new conversational audio AI system being integrated into search, Gemini platform, and developer tools. The advancement in AI conversational capabilities could make it increasingly difficult for users to distinguish between human and AI interactions.
🧠 Gemini
AIBullishMarkTechPost · Mar 267/10
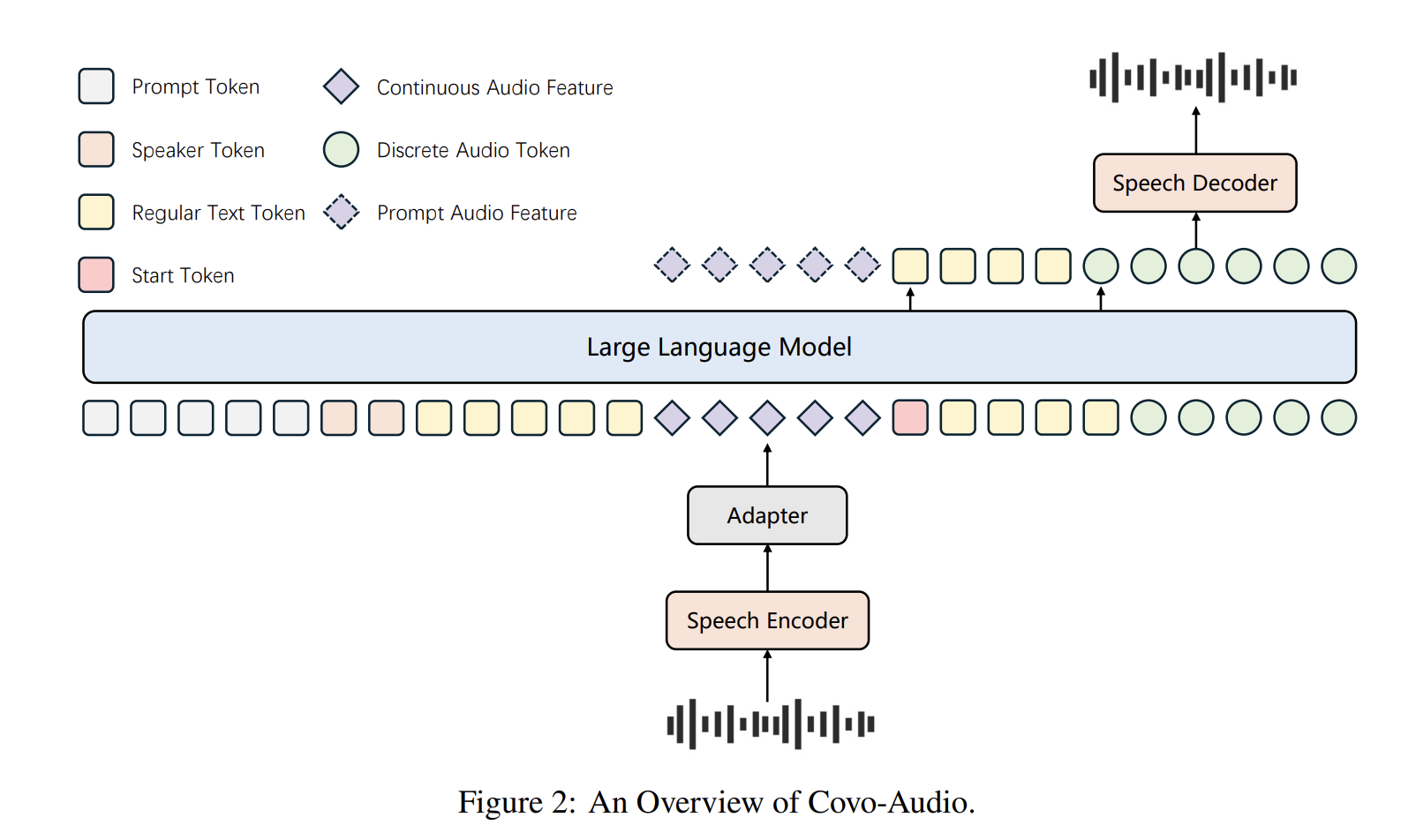
🧠Tencent AI Lab has open-sourced Covo-Audio, a 7B-parameter Large Audio Language Model that can process continuous audio inputs and generate audio outputs in real-time. The model unifies speech processing and language intelligence within a single end-to-end architecture designed for seamless cross-modal interaction.
AIBullisharXiv – CS AI · Mar 57/10
🧠Researchers have developed a new method called Latent-Control Heads (LatCHs) that enables efficient control of audio generation in diffusion models with significantly reduced computational costs. The approach operates directly in latent space, avoiding expensive decoder steps and requiring only 7M parameters and 4 hours of training while maintaining audio quality.
AIBearisharXiv – CS AI · Mar 46/102
🧠Researchers developed a new AI attack method that can fool speaker recognition systems with 10x fewer attempts than previous approaches. The technique uses feature-aligned inversion to optimize attacks in latent space, achieving up to 91.65% success rate with only 50 queries.
AIBullishTechCrunch – AI · Feb 277/107
🧠AI music generator Suno has reached 2 million paid subscribers and achieved $300 million in annual recurring revenue. The platform allows users to create music using natural language prompts, making music generation accessible to users without musical experience.
AIBullishGoogle DeepMind Blog · May 207/105
🧠Google announces Gemma 3n preview, a new open-source AI model optimized for mobile devices with multimodal capabilities including audio processing. The model features a unique 2-in-1 architecture designed to enable fast, interactive AI applications directly on devices.
AINeutralarXiv – CS AI · Jun 256/10
🧠Researchers introduce CASU, a new benchmark for evaluating Large Audio Language Models' ability to understand complex auditory scenes by integrating multiple acoustic layers—speech, sound events, and background environments—rather than processing them in isolation. The benchmark reveals that current LALMs struggle with holistic scene comprehension and require integration across all audio layers for effective real-world audio understanding.
AIBullisharXiv – CS AI · Jun 256/10
🧠Researchers introduce CrossAccent-TTS, a machine learning framework that enables precise control over accent characteristics in cross-lingual text-to-speech systems. The technology uses an Accent Intensity Controller to allow smooth interpolation between accents while maintaining speaker identity, with particular applications for low-resource Indic languages.
AINeutralarXiv – CS AI · Jun 236/10
🧠Researchers introduce AOR-Bench, the first benchmark measuring over-refusal in Large Audio Language Models (LALMs), where safety mechanisms incorrectly reject benign queries. Testing 12 models across six families reveals widespread over-refusal, particularly when audio context could disambiguate potentially harmful speech, prompting exploration of mitigation strategies like Chain-of-Thought reasoning.
AINeutralarXiv – CS AI · Jun 106/10
🧠Researchers introduce DeRA-MOS, a new framework for evaluating text-to-music generation systems that uses decoupled listwise ranking and modality alignment instead of traditional point-wise regression. The approach significantly improves accuracy in assessing both music quality and text-alignment metrics, reducing reliance on expensive human evaluation.
AINeutralarXiv – CS AI · Jun 106/10
🧠Researchers have developed an automated system for evaluating Korean toddler pronunciation using speaker diarization and self-supervised learning models, addressing a significant gap in speech assessment tools for this demographic. The system achieved balanced accuracies of 0.720 for consonants and 0.845 for vowels by routing predictions through specialized SSL models, offering potential clinical applications for detecting speech sound disorders affecting nearly half of Korean pediatric cases.
AINeutralarXiv – CS AI · Jun 56/10
🧠Researchers introduce F3-Tokenizer, a novel audio processing system that combines continuous autoencoders with representation learning to enable both semantic understanding and high-quality audio generation. The approach uses noise-regularized bottlenecks and frozen-LLM supervision to bridge the gap between reconstruction quality and meaningful latent representations.
AINeutralarXiv – CS AI · Jun 25/10
🧠Researchers introduce HRTFformer, a transformer-based neural network that improves the spatial upsampling of Head-Related Transfer Functions (HRTFs) used in immersive audio applications. By leveraging attention mechanisms and spherical harmonic domain processing, the model reconstructs high-fidelity spatial audio from sparse measurements with improved accuracy and realistic spatial coherence.
AINeutralarXiv – CS AI · Jun 26/10
🧠Researchers analyzed how voice cloning technology preserves accented speech compared to standard speech, finding that clones of accented speakers show larger perceptual differences from originals despite similar baseline-normalized embedding distances. The study reveals that accent variation significantly impacts perceived speaker identity and intelligibility in voice cloning systems, suggesting current speaker-discriminative embeddings don't fully capture accent preservation.
AINeutralarXiv – CS AI · Apr 136/10
🧠Researchers propose Noise-Aware In-Context Learning (NAICL), a plug-and-play method to reduce hallucinations in auditory large language models without expensive fine-tuning. The approach uses a noise prior library to guide models toward more conservative outputs, achieving a 37% reduction in hallucination rates while establishing a new benchmark for evaluating audio understanding systems.
AIBullishCrypto Briefing · Apr 106/10
🧠Shubham Saboo discusses three emerging technologies reshaping AI capabilities: the Plod device for audio context capture, OpenClaw for enhanced AI agent functionalities, and effective onboarding strategies. These innovations enable AI agents to autonomously manage business operations and streamline workflows with improved productivity and efficiency.
AIBullisharXiv – CS AI · Mar 266/10
🧠Researchers developed novel 'dropin' and 'plasticity' algorithms inspired by brain neuroplasticity to improve deepfake audio detection efficiency. The methods dynamically adjust neuron counts in model layers, achieving up to 66% reduction in error rates while improving computational efficiency across multiple architectures including ResNet and Wav2Vec.
AINeutralarXiv – CS AI · Mar 126/10
🧠Researchers propose HIR-SDD, a new framework combining Large Audio Language Models with human-inspired reasoning to detect speech deepfakes. The method aims to improve generalization across different audio domains and provide interpretable explanations for deepfake detection decisions.
AINeutralarXiv – CS AI · Mar 116/10
🧠Researchers introduce SCENEBench, a new benchmark for evaluating Large Audio Language Models (LALMs) beyond speech recognition, focusing on real-world audio understanding including background sounds, noise localization, and vocal characteristics. Testing of five state-of-the-art models revealed significant performance gaps, with some tasks performing below random chance while others achieved high accuracy.
AIBullisharXiv – CS AI · Mar 55/10
🧠Researchers have developed MeanFlowSE, a new generative AI model for speech enhancement that performs single-step inference instead of requiring multiple computational steps. The method achieves strong audio quality with substantially lower computational costs, making it suitable for real-time applications without needing knowledge distillation or external teachers.
AIBullisharXiv – CS AI · Mar 27/1012
🧠Researchers have introduced Hello-Chat, an end-to-end audio language model designed to create more realistic and emotionally resonant AI conversations. The model addresses the robotic nature of existing Large Audio Language Models by using real-life conversation data and achieving breakthrough performance in prosodic naturalness and emotional alignment.
AIBullishGoogle DeepMind Blog · Jun 35/104
🧠Gemini 2.5 introduces new AI-powered audio dialog and generation capabilities, expanding Google's multimodal AI offerings. This represents an incremental advancement in conversational AI technology with enhanced audio processing features.