AINeutralOpenAI News · Sep 297/102
🧠OpenAI is implementing comprehensive measures to combat online child sexual exploitation and abuse through strict usage policies, advanced detection technologies, and industry collaboration. The company focuses on blocking, reporting, and preventing the misuse of AI systems for harmful content creation.
AINeutralarXiv – CS AI · Jun 256/10
🧠Researchers evaluated whether fine-tuned encoder classifiers can effectively replace expensive LLM-based judges for detecting harmful outputs in large language models. The study benchmarked ModernBERT family encoders against LLM judges and rule-based methods across adversarial datasets, finding that encoders offer a cost- and latency-efficient alternative for safety evaluation in production environments.
🧠 Claude
AIBearishCrypto Briefing · Jun 246/10
🧠The Washington Post conducted testing of major AI chatbots and found most exhibited left-leaning political bias in their responses. The findings highlight growing concerns about AI neutrality, which is becoming a competitive differentiator as regulatory scrutiny intensifies around algorithmic fairness and bias.
AIBearisharXiv – CS AI · Jun 236/10
🧠Researchers evaluated the vulnerability of AI-generated text detection methods to paraphrasing attacks, finding that while Binoculars-based ensemble classifiers perform best overall, they suffer the greatest performance degradation under adversarial paraphrasing. The study reveals a fundamental trade-off between detection accuracy and resilience in current AI text detection technologies.
AINeutralarXiv – CS AI · Jun 236/10
🧠Researchers introduce AOR-Bench, the first benchmark measuring over-refusal in Large Audio Language Models (LALMs), where safety mechanisms incorrectly reject benign queries. Testing 12 models across six families reveals widespread over-refusal, particularly when audio context could disambiguate potentially harmful speech, prompting exploration of mitigation strategies like Chain-of-Thought reasoning.
AINeutralarXiv – CS AI · Jun 236/10
🧠A research study examines how Google's AI Overviews impact Reddit engagement by comparing Safe-for-Work communities (included in AI summaries) against Not-Safe-for-Work communities (excluded due to content policy). Findings show AI Overviews increase comments by 12% and commenting users by 12.4% in SFW communities, but primarily for experience-based content like advice and personal stories rather than factual information.
🏢 Google
AINeutralarXiv – CS AI · Jun 196/10
🧠Researchers developed a multi-agent simulation framework combining Large Language Models and Genetic Algorithms to study how social media users evolve language strategies to evade platform moderation policies. The study demonstrates that evasion tactics become more sophisticated over iterative exchanges, with validated real-world relevance through user studies.
AINeutralCrypto Briefing · Jun 186/10
🧠An anti-deepfake bill has advanced to the Senate floor, introducing new regulatory requirements for AI-generated content. The legislation's swift passage reflects growing Congressional momentum on AI regulation and signals broader policy shifts that may accelerate future technology oversight.
AIBullishFortune Crypto · Jun 116/10
🧠Anthropic has committed to notifying users when their requests are rejected or degraded due to national security concerns, reversing a previous approach where such actions occurred silently. This policy shift addresses transparency concerns raised by critics who argued users deserve to know when content moderation is applied for security reasons.
🏢 Anthropic
AIBearishCrypto Briefing · Jun 106/10
🧠A MIT study reveals that users who rely on AI tools for detecting misinformation experience a decline in their ability to independently identify fake news. This finding raises concerns about cognitive skill atrophy and highlights potential risks to informed decision-making as AI-assisted content moderation becomes more prevalent.
GeneralNeutralCrypto Briefing · Jun 106/10
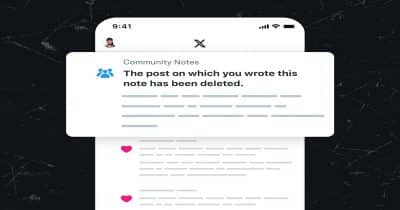
📰X has introduced a memory feature that proactively notifies users when Community Notes corrections apply to previously viewed posts. While this advancement could strengthen misinformation control on the platform, declining contributor engagement threatens to undermine both the program's effectiveness and the credibility of the correction mechanism itself.
AINeutralarXiv – CS AI · Jun 106/10
🧠Researchers have developed an unsupervised method for detecting AI-generated text by learning style representations through paraphrase inversion, without requiring authorship labels. The approach demonstrates competitive performance in both few-shot and zero-shot detection scenarios while generalizing better to unseen language models than existing supervised methods.
AINeutralarXiv – CS AI · Jun 106/10
🧠Researchers propose lightweight token-level probes that monitor LLM safety directly within model hidden states during generation, eliminating the computational overhead of separate moderation models. This streaming approach enables real-time intervention before unsafe content completes generation, reducing inference costs by orders of magnitude while maintaining safety standards.
AINeutralarXiv – CS AI · Jun 106/10
🧠Researchers demonstrate that while machine-text detection evasion attacks can fool standard detectors, stylistic fingerprints of AI-generated content remain detectable through few-shot learning methods. However, a novel paraphrasing approach that mimics human writing styles can evade all current detectors, though multi-document analysis reveals the deception at scale.
AINeutralArs Technica – AI · Jun 96/10
🧠Anthropic's Claude Fable 5 model implements restrictions on discussing cybersecurity, biology, and chemistry topics, reflecting the AI industry's growing approach to content safety through deliberate capability limitations. This decision highlights the tension between AI capability development and responsible deployment practices.
🏢 Anthropic
AINeutralarXiv – CS AI · Jun 95/10
🧠Researchers presented a study on detecting hate speech and analyzing sentiment in Nepali-language memes using transformer-based machine learning models and ensemble learning techniques. The work addresses challenges specific to Nepali text analysis, including code-mixing and limited baseline datasets, demonstrating that soft voting ensemble strategies outperform standalone models for multi-class sentiment tasks by 15.8% in Macro F1-score.
AIBearisharXiv – CS AI · Jun 96/10
🧠A research paper examines AI-generated "fruit dramas"—short videos featuring anthropomorphized characters distributed algorithmically on social media—arguing they embed problematic gendered and racialized narratives while using cute aesthetics to evade content moderation systems.
AINeutralarXiv – CS AI · Jun 96/10
🧠Researchers address the overlooked problem of annotator disagreement in hate speech classification, demonstrating that traditional approaches discarding non-consensus samples produce inflated performance metrics. The study establishes new state-of-the-art results for Turkish tweet classification by properly modeling disagreement as a valuable signal rather than noise, using aggregation methods and perceived hate speech strength scores to build more robust detection systems.
AIBearishThe Verge – AI · Jun 66/10
🧠Meta has launched a "For You" section in its standalone AI app that generates clickbait-style news articles entirely through AI, complete with AI-generated images and text. The move represents Meta's pivot toward AI-generated content feeds, though the quality and accuracy of such content remains questionable.
🏢 Meta🧠 ChatGPT
CryptoNeutralDecrypt – AI · Jun 56/10
⛓️Pump.fun has launched GO, a bounty platform allowing users to pay anyone to complete arbitrary tasks, which has already attracted hundreds of listings. The platform's permissive approach to task creation is generating unusual and potentially problematic use cases, highlighting tensions between decentralized platforms and content moderation.
AIBearishFortune Crypto · Jun 56/10
🧠Businesses are increasingly deploying detection tools to combat AI-generated content flooding the web, but face a technological arms race where content generation tools continuously evolve to evade detection. This ongoing conflict raises questions about the feasibility of large-scale content moderation as AI systems become more sophisticated.
AINeutralarXiv – CS AI · Jun 56/10
🧠Researchers propose RidgeFT, a machine learning framework that enables continuous identification of machine-generated text sources while preserving performance on previously learned generators. The method uses efficient closed-form updates and feature-stable analytics to balance adaptation to new language models with retention of old ones.
AINeutralarXiv – CS AI · Jun 56/10
🧠Researchers introduce UNIVID, a unified vision-language model designed for large-scale video moderation that generates interpretable policy-aware captions instead of opaque classification outputs. The system reduces violation detection errors by 42.7% and false positives by 37.0% while consolidating over 1,000 specialized models into a single backbone, demonstrating practical AI efficiency gains in content moderation infrastructure.
AINeutralHugging Face Blog · Jun 46/10
🧠NVIDIA releases Nemotron 3.5 Content Safety, a customizable multimodal safety framework designed to help enterprises deploy AI systems with tailored content moderation across text and images. The tool addresses the challenge of balancing safety requirements across different global markets and use cases, enabling developers to configure safety policies without extensive retraining.
AINeutralarXiv – CS AI · Jun 46/10
🧠Researchers propose a framework for multi-agent systems that treats disagreement as valuable information rather than error to be eliminated. The approach abstracts reasoning traces into four symbolic disagreement states and applies strategic routing rules to content moderation and AI collaboration tasks.