AIBullisharXiv – CS AI · Jun 47/10
🧠Researchers propose principle-driven foundation models that encode physics-based principles rather than learn statistical correlations, achieving cross-modal transfer from radio-frequency data to audio, images, text, and video without fine-tuning. A 1.99M parameter frozen encoder reaches 77.7% average accuracy across 15 tasks, with performance varying systematically between physically-grounded (84.5%) and semantic tasks (70.0%), suggesting complementary approaches to AI generalization.
AIBullishMarkTechPost · Mar 267/10
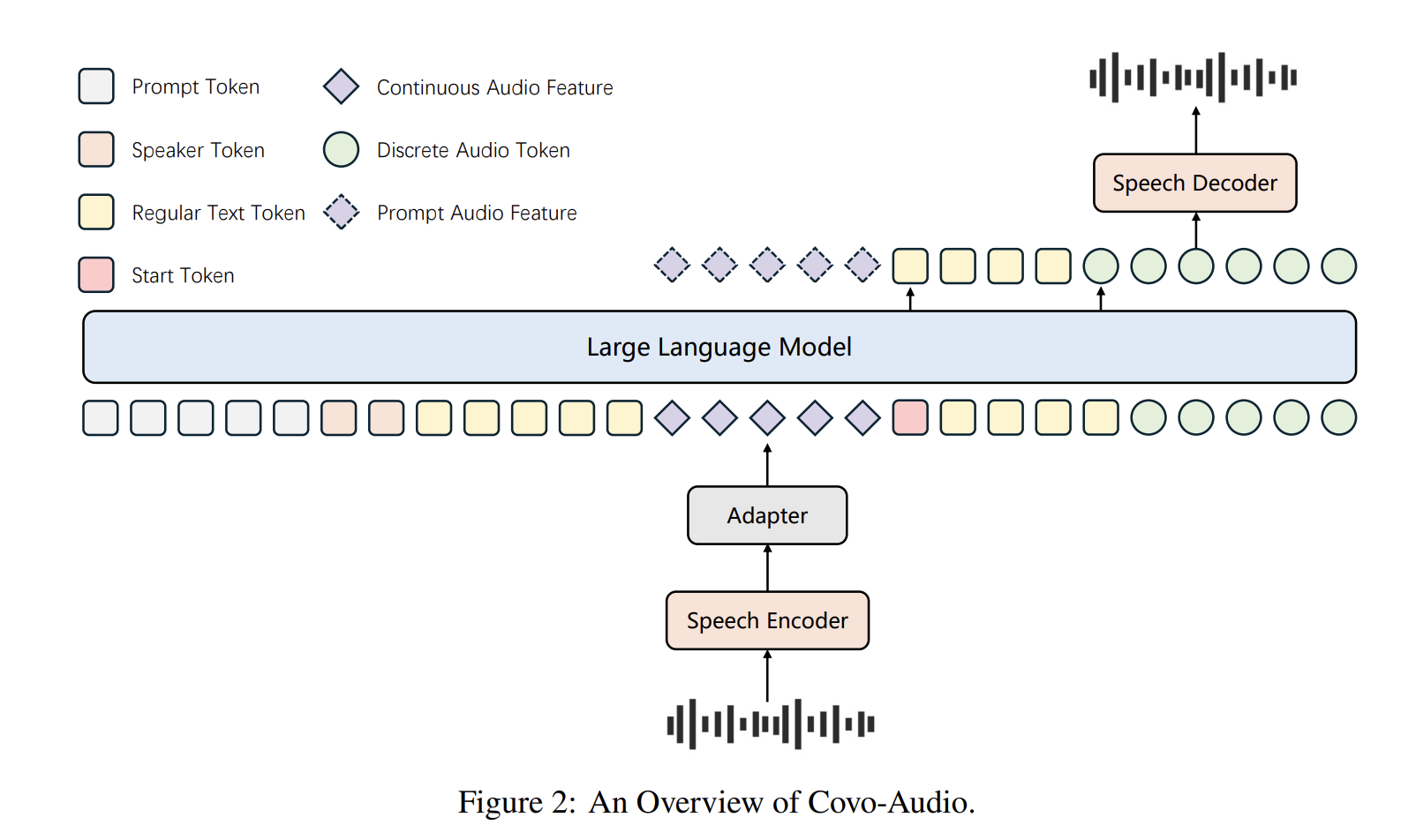
🧠Tencent AI Lab has open-sourced Covo-Audio, a 7B-parameter Large Audio Language Model that can process continuous audio inputs and generate audio outputs in real-time. The model unifies speech processing and language intelligence within a single end-to-end architecture designed for seamless cross-modal interaction.
AIBullisharXiv – CS AI · Mar 267/10
🧠Researchers have released DanQing, a large-scale Chinese vision-language dataset containing 100 million high-quality image-text pairs curated from Common Crawl data. The dataset addresses the bottleneck in Chinese VLP development and demonstrates superior performance compared to existing Chinese datasets across various AI tasks.
AIBullisharXiv – CS AI · Mar 117/10
🧠Researchers introduce MMGraphRAG, a new AI framework that addresses hallucination issues in large language models by integrating visual scene graphs with text knowledge graphs through cross-modal fusion. The system uses SpecLink for entity linking and demonstrates superior performance in multimodal information processing across multiple benchmarks.
AIBullisharXiv – CS AI · Mar 97/10
🧠Researchers introduced SPARC, a framework that creates unified latent spaces across different AI models and modalities, enabling direct comparison of how various architectures represent identical concepts. The method achieves 0.80 Jaccard similarity on Open Images, tripling alignment compared to previous methods, and enables practical applications like text-guided spatial localization in vision-only models.
AIBullisharXiv – CS AI · Feb 277/106
🧠Researchers developed a theoretical framework to optimize cross-modal fine-tuning of pre-trained AI models, addressing the challenge of aligning new feature modalities with existing representation spaces. The approach introduces a novel concept of feature-label distortion and demonstrates improved performance over state-of-the-art methods across benchmark datasets.
AINeutralarXiv – CS AI · Jun 106/10
🧠Researchers introduce DeRA-MOS, a new framework for evaluating text-to-music generation systems that uses decoupled listwise ranking and modality alignment instead of traditional point-wise regression. The approach significantly improves accuracy in assessing both music quality and text-alignment metrics, reducing reliance on expensive human evaluation.
AINeutralarXiv – CS AI · May 126/10
🧠Researchers introduce KARMA-MV, a large-scale dataset of 37,737 multiple-choice questions derived from 2,682 YouTube music videos, designed to benchmark AI models' ability to reason about causal relationships between visual dynamics and musical structure. The dataset leverages LLM-based generation for scalability and proposes a causal knowledge graph approach to improve vision-language model performance on cross-modal audio-visual reasoning tasks.
AINeutralarXiv – CS AI · Apr 156/10
🧠Researchers demonstrate that MMA2A, a multimodal routing protocol for agent-to-agent networks, achieves 52% task accuracy versus 32% for text-only baselines by preserving native modalities (voice, image, text) across agent boundaries. The 20-percentage-point improvement requires both protocol-level native routing and capable downstream reasoning agents, establishing routing as a critical design variable in multi-agent systems.
$TCA
AIBullisharXiv – CS AI · Mar 276/10
🧠Researchers introduce RC2, a reinforcement learning framework that improves multimodal AI reasoning by enforcing consistency between visual and textual representations. The system uses cycle-consistent training to resolve internal conflicts between modalities, achieving up to 7.6 point improvements in reasoning accuracy without requiring additional labeled data.
AIBullisharXiv – CS AI · Mar 276/10
🧠Researchers propose X-OPD, a Cross-Modal On-Policy Distillation framework to improve Speech Large Language Models by aligning them with text-based counterparts. The method uses token-level feedback from teacher models to bridge performance gaps in end-to-end speech systems while preserving inherent capabilities.
AINeutralarXiv – CS AI · Mar 176/10
🧠Researchers introduce FL-I2MoE, a new Mixture-of-Experts layer for multimodal Transformers that explicitly identifies synergistic and redundant cross-modal feature interactions. The method provides more interpretable explanations for how different data modalities contribute to AI decision-making compared to existing approaches.
AIBullisharXiv – CS AI · Mar 176/10
🧠Researchers propose ES-Merging, a new framework for combining specialized biological multimodal large language models (MLLMs) by using embedding space signals rather than traditional parameter-based methods. The approach estimates merging coefficients at both layer-wise and element-wise granularities, outperforming existing merging techniques and even task-specific fine-tuned models on cross-modal scientific problems.
AIBullisharXiv – CS AI · Mar 116/10
🧠Facebook Research introduces the Latent Speech-Text Transformer (LST), which aggregates speech tokens into higher-level patches to improve computational efficiency and cross-modal alignment. The model achieves up to +6.5% absolute gain on speech HellaSwag benchmarks while maintaining text performance and reducing inference costs for ASR and TTS tasks.
AIBullisharXiv – CS AI · Mar 96/10
🧠Researchers introduce CoE, a training-free multimodal summarization framework that uses a Chain-of-Events approach with Hierarchical Event Graph to better understand and summarize content across videos, transcripts, and images. The system achieves significant performance improvements over existing methods, showing average gains of +3.04 ROUGE, +9.51 CIDEr, and +1.88 BERTScore across eight datasets.
AIBullisharXiv – CS AI · Mar 37/108
🧠Researchers propose a training-free paradigm for empowering Vision-Language Models with multi-modal search capabilities through cross-modal model merging. The approach uses Optimal Brain Merging (OBM) to combine text-based search agents with base VLMs without requiring expensive supervised training or reinforcement learning.
AIBullisharXiv – CS AI · Mar 26/1015
🧠Researchers have developed an 'Omnivorous Vision Encoder' that creates consistent feature representations across different visual modalities (RGB, depth, segmentation) of the same scene. The framework addresses the poor cross-modal alignment in existing vision encoders like DINOv2 by training with dual objectives to maximize feature alignment while preserving discriminative semantics.
AIBullisharXiv – CS AI · Feb 276/106
🧠Researchers introduced ViCLIP-OT, the first foundation vision-language model specifically designed for Vietnamese image-text retrieval. The model integrates CLIP-style contrastive learning with Similarity-Graph Regularized Optimal Transport (SIGROT) loss, achieving significant improvements over existing baselines with 67.34% average Recall@K on UIT-OpenViIC benchmark.
AINeutralarXiv – CS AI · Feb 275/107
🧠Researchers conducted a cross-modal study comparing human preference annotations between text and audio formats for AI alignment. The study found that while audio preferences are as reliable as text, different modalities lead to different judgment patterns, with synthetic ratings showing promise as replacements for human annotations.
$NEAR
AINeutralarXiv – CS AI · Feb 276/107
🧠Researchers introduce SPARTA, an automated framework for generating large-scale Table-Text question answering benchmarks that require complex multi-hop reasoning across structured and unstructured data. The benchmark exposes significant weaknesses in current AI models, with state-of-the-art systems experiencing over 30 F1 point performance drops compared to existing simpler datasets.
AIBullisharXiv – CS AI · Feb 276/106
🧠Researchers developed an unbiased sliced Wasserstein RBF kernel with rotary positional embedding to improve audio captioning systems by addressing exposure bias and temporal relationship issues. The method shows significant improvements in caption quality and text-to-audio retrieval accuracy on AudioCaps and Clotho datasets, while also enhancing audio reasoning capabilities in large language models.
AINeutralarXiv – CS AI · Mar 115/10
🧠Researchers introduce Daily-Omni, a new benchmark for evaluating multimodal AI models' ability to process audio and video simultaneously. The study of 24 foundation models reveals that current AI systems struggle with cross-modal temporal alignment, highlighting a key limitation in multimodal reasoning.
AINeutralarXiv – CS AI · Mar 34/103
🧠Researchers introduce Stepping Stone Plus (SSP), a novel framework that combines optical flow and textual prompts to improve audio-visual semantic segmentation. The method outperforms existing approaches by using motion dynamics for moving sound sources and textual descriptions for stationary objects, with a visual-textual alignment module for better cross-modal integration.