AINeutralThe Verge – AI · Jun 277/10
🧠Anthropic's Mythos 5 AI model has been partially reinstated following a two-week negotiation with the Trump administration, becoming available to select organizations through a revised licensing framework. However, the public-facing Fable 5 version remains unavailable with no clear timeline for release, suggesting ongoing regulatory constraints on advanced AI deployment.
🏢 Anthropic
AIBearishFortune Crypto · Jun 267/10
🧠OpenAI has agreed to stagger the rollout of its most advanced model, restricting initial access to customers approved by the Trump administration due to concerns about cybersecurity capabilities. This marks the second instance in a month where a leading AI lab has delayed general availability of its most powerful model over fears of malicious use.
🏢 OpenAI
AIBearishDecrypt · Jun 267/10
🧠OpenAI has launched GPT-5.6 models on Friday, but deployment is restricted to a limited user base due to U.S. government intervention. This represents a significant shift in AI model availability, with regulatory oversight now directly constraining commercial AI rollouts.
🏢 OpenAI🧠 GPT-5
AI × CryptoBullishCrypto Briefing · Jun 17/10
🤖Tether AI has open-sourced TurboQuant, a technology that reduces large language model KV cache memory consumption by 5x. The release aims to democratize AI development by enabling efficient local deployment and reducing dependence on centralized cloud infrastructure.
AINeutralarXiv – CS AI · Jun 17/10
🧠A comprehensive research study reveals that Retrieval-Augmented Generation (RAG) systems require context-aware deployment strategies rather than universal approaches. The analysis across multiple LLMs and datasets shows that RAG effectiveness depends heavily on task type, with optimal retrieval volumes and knowledge integration methods varying significantly between question answering and code generation applications.
AIBullisharXiv – CS AI · May 127/10
🧠Researchers introduce Mixed-Policy Distillation (MPD), a technique that compresses reasoning in smaller language models by having larger teacher models rewrite student-generated reasoning traces into more concise versions. The method reduces token usage by up to 27.1% while maintaining or improving performance, addressing critical deployment constraints around memory, latency, and serving costs.
AIBullisharXiv – CS AI · Apr 77/10
🧠Researchers propose SoLA, a training-free compression method for large language models that combines soft activation sparsity and low-rank decomposition. The method achieves significant compression while improving performance, demonstrating 30% compression on LLaMA-2-70B with reduced perplexity from 6.95 to 4.44 and 10% better downstream task accuracy.
🏢 Perplexity
AIBullishMarkTechPost · Mar 167/10
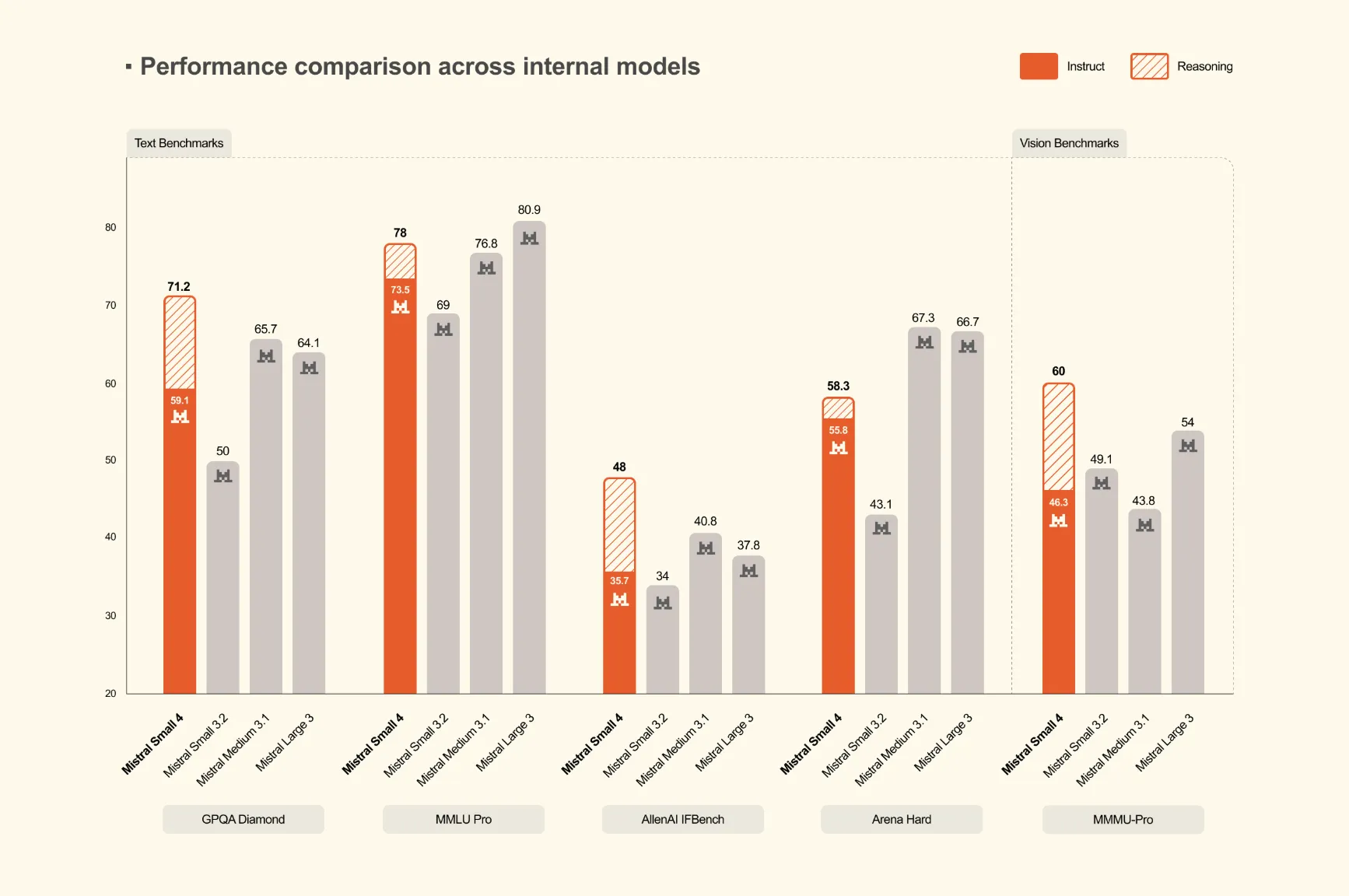
🧠Mistral AI has launched Mistral Small 4, a 119-billion parameter Mixture of Experts (MoE) model that unifies instruction following, reasoning, and multimodal capabilities into a single deployment. This represents the first model from Mistral to consolidate the functions of their previously separate Mistral Small, Magistral, and Pixtral models.
🏢 Mistral
AINeutralarXiv – CS AI · Mar 37/104
🧠Researchers analyzed 20 Mixture-of-Experts (MoE) language models to study local routing consistency, finding a trade-off between routing consistency and local load balance. The study introduces new metrics to measure how well expert offloading strategies can optimize memory usage on resource-constrained devices while maintaining inference speed.
AINeutralarXiv – CS AI · Jun 256/10
🧠This arXiv paper proposes a framework for Industrial Continual Learning (ICL) in large language models, addressing the challenge of continuously updating deployed models without retraining from scratch. The research identifies three core technical challenges—model plasticity erosion, capability inheritance breaks during upgrades, and deployment sustainability constraints—and proposes five lifecycle design principles to guide industrial LLM development and evolution.
AIBullishCrypto Briefing · Jun 246/10
🧠Qualcomm has expanded its partnership with Hugging Face to facilitate AI model deployment across edge and cloud environments. The collaboration aims to streamline AI integration into Qualcomm's hardware ecosystem, potentially increasing demand for the company's processors and accelerators across diverse computing platforms.
🏢 Hugging Face
AINeutralarXiv – CS AI · Jun 236/10
🧠Researchers investigate the energy consumption trade-offs of Unsupervised Domain Adaptation (UDA) versus retraining in 6G wireless networks, proposing a framework to determine when UDA becomes more energy-efficient when accounting for labeling costs and multiple target domains.
AINeutralarXiv – CS AI · Jun 196/10
🧠Researchers introduce SEVRA, a serving-layer system that selectively decides whether to verify AI reasoning outputs, reducing computational waste while maintaining accuracy. The approach achieves comparable or better results than always-verifying strategies while cutting token usage significantly, though longer initial reasoning sometimes proves more efficient overall.
AIBearishThe Verge – AI · Jun 106/10
🧠Anthropic's newly released Claude Fable 5 model deliberately refuses to answer basic biology questions despite being marketed as highly capable in biology, instead routing queries to the older Claude Opus 4.8. The design choice reflects Anthropic's cautious approach to deploying a powerful Mythos-class model that was previously deemed too dangerous for public release due to its cybersecurity capabilities.
🏢 Anthropic🧠 Claude🧠 Opus
AIBearishStratechery · Jun 106/10
🧠Fable 5, the public release of Anthropic's Mythos model, demonstrates significant AI capabilities but introduces concerning precedents around alignment and safety standards. The release raises questions about how advanced AI systems are being deployed and governed.
🏢 Anthropic
AINeutralarXiv – CS AI · Jun 96/10
🧠Researchers propose 'kernel contracts,' a framework for managing divergence between training and inference implementations of AI models that operate at different precision levels. The work formalizes how finite-precision optimizations can produce different outputs at identical weights and provides mathematical bounds on resulting policy drift, with implications for reliable AI deployment.
AINeutralarXiv – CS AI · May 96/10
🧠Researchers propose a regime theory framework for selecting controller classes in language and vision-language models, determining whether AI systems should answer directly, retrieve evidence, defer to stronger models, or abstain. The work demonstrates that model expressivity doesn't uniformly improve performance in finite samples, and provides a principled method to match controller complexity to data availability across multiple benchmarks.
AINeutralarXiv – CS AI · Apr 146/10
🧠A-IO addresses critical memory-bound bottlenecks in LLM deployment on NPU platforms like Ascend 910B by tackling the 'Model Scaling Paradox' and limitations of current speculative decoding techniques. The research reveals that static single-model deployment strategies and kernel synchronization overhead significantly constrain inference performance on heterogeneous accelerators.
AINeutralarXiv – CS AI · Apr 146/10
🧠Gypscie is a new cross-platform AI artifact management system that unifies the complexity of managing machine learning models across diverse infrastructure through a knowledge graph and rule-based query language. The system streamlines the entire AI model lifecycle—from data preparation through deployment and monitoring—while enabling explainability through provenance tracking.
AINeutralAI News · Apr 136/10
🧠Enterprise security leaders face growing challenges securing edge AI deployments as models like Google Gemma 4 proliferate beyond traditional cloud infrastructure. Organizations built robust cloud security perimeters but now struggle to govern AI workloads running on distributed edge systems, requiring new governance approaches.
AIBullisharXiv – CS AI · Mar 266/10
🧠Researchers propose APreQEL, an adaptive mixed precision quantization method for deploying large language models on edge devices. The approach optimizes memory, latency, and accuracy by applying different quantization levels to different layers based on their importance and hardware characteristics.
AIBullisharXiv – CS AI · Mar 37/1010
🧠TriMoE introduces a novel GPU-CPU-NDP architecture that optimizes large Mixture-of-Experts model inference by strategically mapping hot, warm, and cold experts to their optimal compute units. The system leverages AMX-enabled CPUs and includes bottleneck-aware scheduling, achieving up to 2.83x performance improvements over existing solutions.
AIBullishHugging Face Blog · Jul 216/105
🧠NVIDIA has partnered with Hugging Face to integrate NIM (NVIDIA Inference Microservices) to accelerate large language model deployment and inference. This collaboration aims to make AI model deployment more efficient and accessible through optimized GPU acceleration on the Hugging Face platform.
AIBullishHugging Face Blog · Jul 296/105
🧠Hugging Face has partnered with NVIDIA to integrate NIM (NVIDIA Inference Microservices) for serverless AI model inference. This collaboration enables developers to deploy and scale AI models more efficiently using NVIDIA's optimized inference infrastructure through Hugging Face's platform.
AIBullishHugging Face Blog · Jun 76/106
🧠Hugging Face has launched a new Embedding Container for Amazon SageMaker, enabling easier deployment of embedding models in AWS cloud infrastructure. This integration streamlines the process for developers to implement text embeddings and vector search capabilities in production environments.