AINeutralarXiv – CS AI · May 296/10
🧠Researchers introduced UA-Legal-Bench, a five-task benchmark for evaluating large language models on Ukrainian legal reasoning using 99.5 million court decisions. The study reveals critical gaps in LLM evaluation for morphologically rich, non-Latin-script languages and demonstrates that standard accuracy metrics mask poor performance on imbalanced legal tasks.
AINeutralarXiv – CS AI · May 126/10
🧠Researchers introduce Ace-Skill, a co-evolutionary framework that improves multimodal AI agents by optimizing both data sampling and knowledge organization. The system achieves 35% performance gains on tool-use benchmarks and enables smaller models to inherit capabilities from larger ones without additional training.
AINeutralarXiv – CS AI · May 126/10
🧠Researchers introduce TRACE, a novel training method that improves AI model performance by selectively applying different optimization techniques to critical versus routine tokens in reasoning tasks. The approach addresses inefficiencies in standard self-distillation by concentrating training effort on important decision points, achieving 2.76 percentage point improvements over baseline methods while better preserving out-of-distribution generalization.
AIBullisharXiv – CS AI · May 126/10
🧠Researchers introduce LEVI, an open-source evolutionary search framework that achieves superior results on AI research benchmarks while reducing computational costs by 3.3x to 35x compared to existing methods. By optimizing search architecture rather than relying on larger language models, LEVI demonstrates that algorithmic efficiency can significantly reduce the expense of LLM-guided evolutionary discovery.
AINeutralarXiv – CS AI · May 116/10
🧠Researchers introduce SCALAR, an Actor-Critic-Judge framework that systematically evaluates how AI agents improve through human feedback on theoretical physics problems. The study reveals that multi-turn dialogue consistently outperforms single attempts, but the effectiveness of different feedback strategies depends heavily on the specific pairing of AI models used, with asymmetric model pairs benefiting most from structured critique.
AINeutralarXiv – CS AI · May 96/10
🧠Researchers introduce Strat-LLM, a framework that aligns large language models for stock trading by matching model architecture to operational modes (Free, Guided, Strict), finding that reasoning-heavy models excel with minimal constraints while standard models benefit from strict guardrails. Live-forward testing across 2025 on A-share and U.S. markets reveals that optimal performance depends on market regime and model scale, with mid-size models (35B) showing superior risk-adjusted returns under constraints.
AINeutralarXiv – CS AI · May 76/10
🧠Researchers introduce CreativityBench, a benchmark with 4K entities and 150K+ affordance annotations to evaluate how well large language models can creatively repurpose tools by reasoning about their properties rather than canonical uses. Evaluations across 10 state-of-the-art LLMs reveal significant limitations: models struggle to identify correct parts, affordances, and physical mechanisms needed for non-obvious solutions, with performance gains from scaling and reasoning strategies like Chain-of-Thought proving limited.
AINeutralarXiv – CS AI · Apr 206/10
🧠Researchers conducted a comparative study of how large language models trained with different fine-tuning methods (full fine-tuning, LoRA, and quantized LoRA) interpret code compliance tasks. The study reveals that full fine-tuning produces more focused attribution patterns than parameter-efficient methods, and larger models develop distinct interpretive strategies despite performance gains plateauing above 7B parameters.
AIBullishMarkTechPost · Mar 167/10
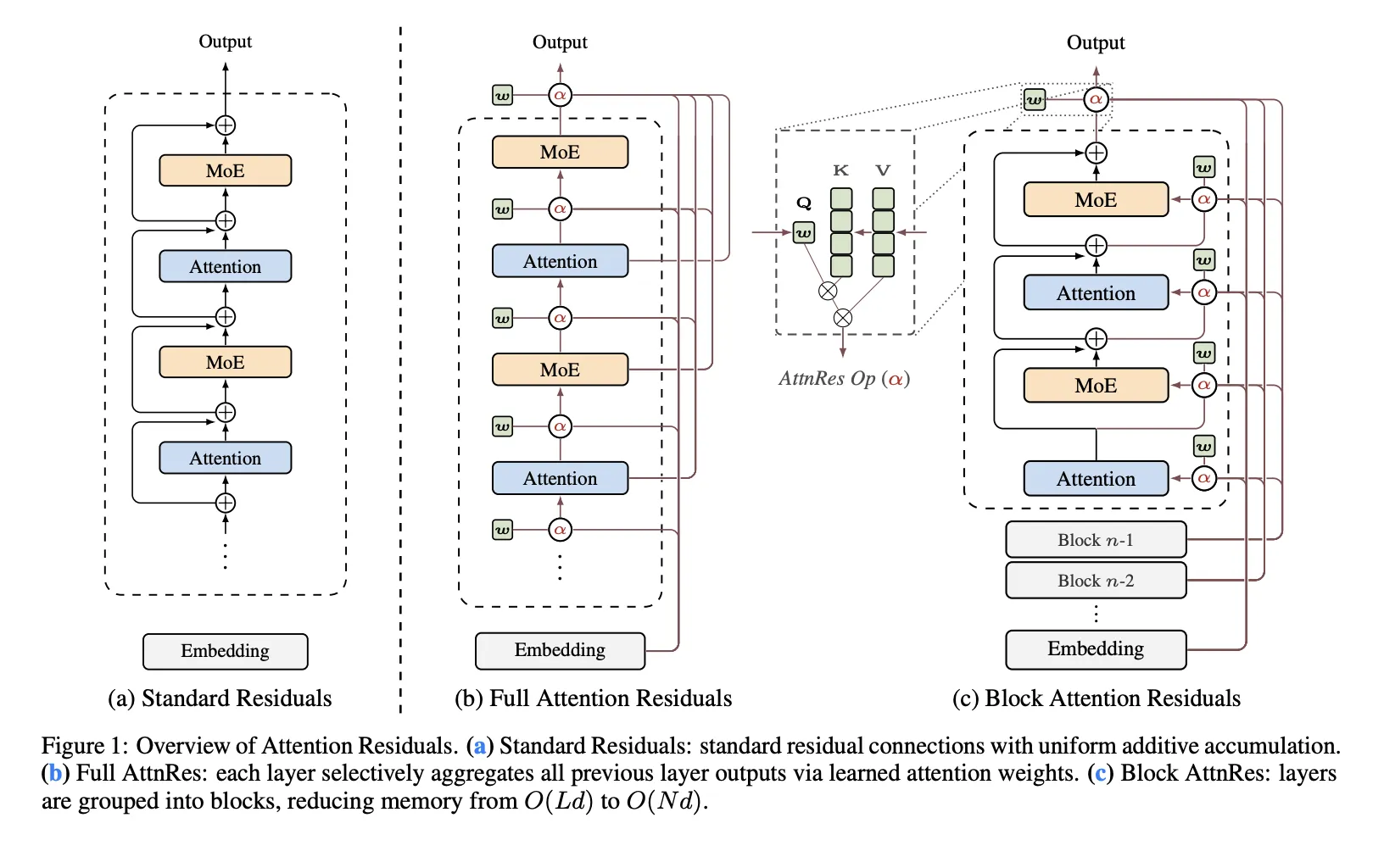
🧠Moonshot AI has released Attention Residuals, a new approach that replaces traditional fixed residual connections in Transformer architectures with depth-wise attention mechanisms. The innovation addresses structural problems in PreNorm architectures where all prior layer outputs are mixed equally, potentially improving model scaling capabilities.
AINeutralarXiv – CS AI · Mar 36/104
🧠Researchers evaluated compact AI language models for 6G networks, finding that mid-scale models (1.5-3B parameters) offer the best balance of performance and computational efficiency for edge deployment. The study shows diminishing returns beyond 3B parameters, with accuracy improving from 22% at 135M to 70% at 7B parameters.