Models, papers, tools. 19,548 articles with AI-powered sentiment analysis and key takeaways.
AIBullishThe Register – AI · Mar 167/10
🧠The UK government has allocated £45 million to fund an AI supercomputer specifically designed to accelerate fusion power research and development. This investment represents a significant commitment to using advanced computing technology to solve one of the world's most challenging energy problems.
AIBullishBlockonomi · Mar 166/10
🧠Alibaba stock is rising following news that the company will launch an enterprise AI agent this week. The AI agent is built on the Qwen platform and developed by Alibaba's DingTalk team, marking the company's expansion into enterprise AI solutions.
AIBearishBlockonomi · Mar 166/10
🧠Foxconn shares declined after Q4 profit of $1.41B fell short of analyst expectations, despite achieving record revenue growth. The earnings miss occurred even as the company benefited from strong AI server manufacturing demand.
GeneralBearishFortune Crypto · Mar 167/10
📰Ray Dalio warns that current global conditions resemble pre-1945 times, suggesting we are approaching the end of his theoretical 'Big Cycle' framework. This analysis implies potential major geopolitical and economic shifts ahead that could impact global markets and financial systems.
AIBullishMarkTechPost · Mar 167/10
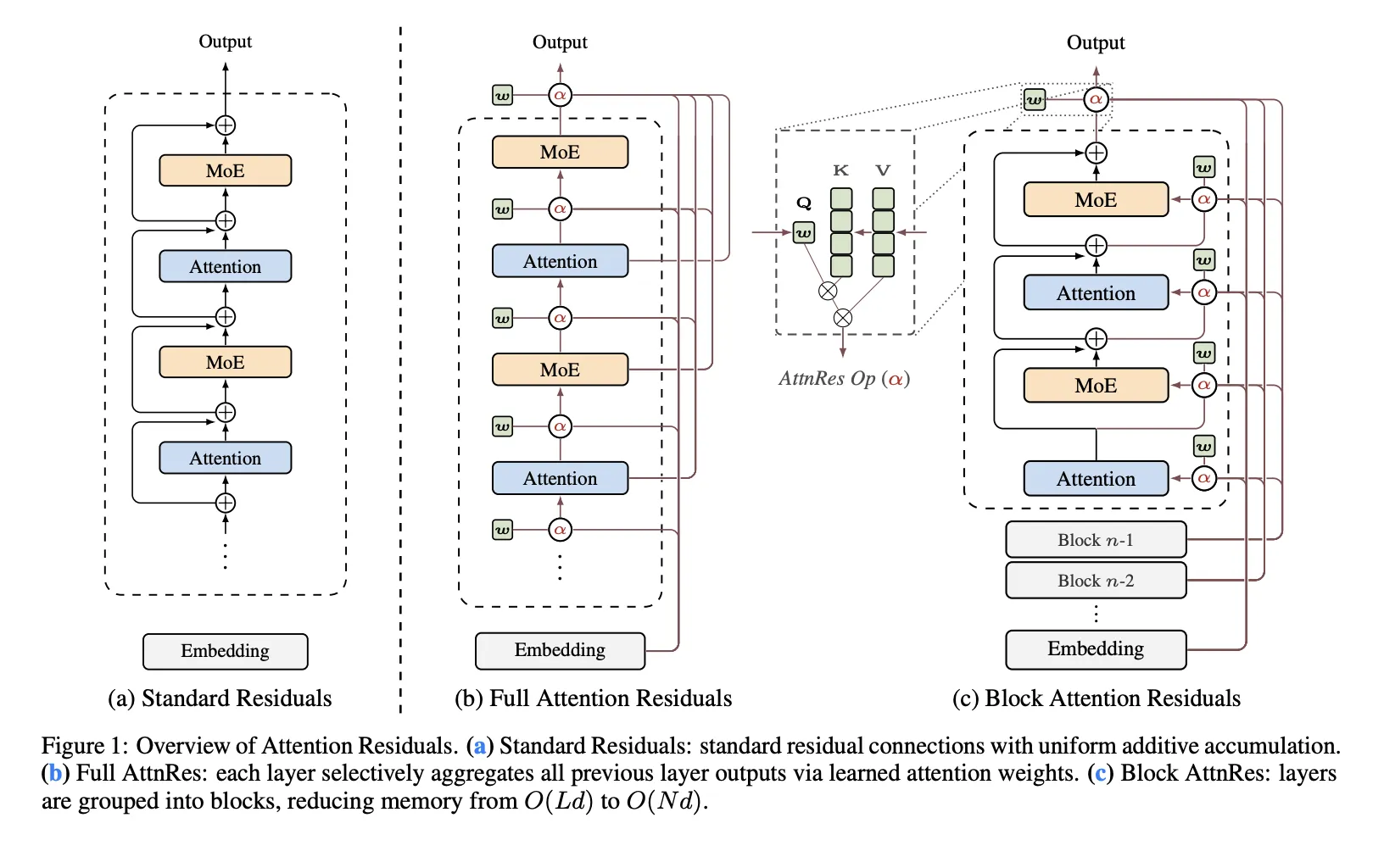
🧠Moonshot AI has released Attention Residuals, a new approach that replaces traditional fixed residual connections in Transformer architectures with depth-wise attention mechanisms. The innovation addresses structural problems in PreNorm architectures where all prior layer outputs are mixed equally, potentially improving model scaling capabilities.
AI × CryptoBearishCoinTelegraph – Regulation · Mar 166/10
🤖Australia's securities regulator reports that 23% of Gen Z owns cryptocurrency, with two-thirds using social media for financial decisions. The regulator warns this social media influence, including AI and 'finfluencers,' is leading to riskier financial choices among younger investors.
AIBullishMarkTechPost · Mar 166/10
🧠IBM has released Granite 4.0 1B Speech, a compact multilingual speech-language model optimized for automatic speech recognition and translation. The model is specifically designed for enterprise and edge deployments where memory efficiency, low latency, and compute optimization are critical alongside performance quality.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers introduce a formal planning framework that maps LLM-based web agents to traditional search algorithms, enabling better diagnosis of failures in autonomous web tasks. The study compares different agent architectures using novel evaluation metrics and a dataset of 794 human-labeled trajectories from WebArena benchmark.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers have developed ToolTree, a new Monte Carlo tree search-based planning system for LLM agents that improves tool selection and usage through dual-feedback evaluation and bidirectional pruning. The system achieves approximately 10% performance gains over existing methods while maintaining high efficiency across multiple benchmarks.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers developed an agentic AI framework using LLMs like Claude Opus 4.6 and GitHub Copilot to automate chemical process flowsheet modeling. The multi-agent system decomposes engineering tasks with one agent solving problems using domain knowledge and another implementing solutions in code for industrial simulations.
🏢 Anthropic🏢 Microsoft🧠 Claude
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers propose AMRO-S, a new routing framework for multi-agent LLM systems that uses ant colony optimization to improve efficiency and reduce costs. The system addresses key deployment challenges like high inference costs and latency while maintaining performance quality through semantic-aware routing and interpretable decision-making.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers developed a structured distillation method that compresses AI agent conversation history by 11x (from 371 to 38 tokens per exchange) while maintaining 96% of retrieval quality. The technique enables thousands of exchanges to fit within a single prompt at 1/11th the context cost, addressing the expensive verbatim storage problem for long AI conversations.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers introduce DART, a new framework for early-exit deep neural networks that achieves up to 3.3x speedup and 5.1x lower energy consumption while maintaining accuracy. The system uses input difficulty estimation and adaptive thresholds to optimize AI inference for resource-constrained edge devices.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers introduce a new knowledge distillation framework that improves training of smaller AI models by using intermediate representations from large language models rather than their final outputs. The method shows consistent improvements across reasoning benchmarks, particularly when training data is limited, by providing cleaner supervision signals.
AIBearisharXiv – CS AI · Mar 166/10
🧠Researchers have identified 'role confusion' as the fundamental mechanism behind prompt injection attacks on language models, where models assign authority based on how text is written rather than its source. The study achieved 60-61% attack success rates across multiple models and found that internal role confusion strongly predicts attack success before generation begins.
AINeutralarXiv – CS AI · Mar 166/10
🧠Researchers propose Global Evolutionary Refined Steering (GER-steer), a new training-free framework for controlling Large Language Models without fine-tuning costs. The method addresses issues with existing activation engineering approaches by using geometric stability to improve steering vector accuracy and reduce noise.
AINeutralarXiv – CS AI · Mar 166/10
🧠Researchers introduce Budget-Sensitive Discovery Score (BSDS), a formally verified framework for evaluating AI-guided scientific candidate selection under budget constraints. Testing on drug discovery datasets reveals that simple random forest models outperform large language models, with LLMs providing no marginal value over existing trained classifiers.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers improved agentic Retrieval-Augmented Generation (RAG) systems by introducing contextualization and de-duplication modules to address inefficiencies in complex question-answering. The enhanced Search-R1 pipeline achieved 5.6% better accuracy and 10.5% fewer retrieval turns using GPT-4.1-mini.
🧠 GPT-4
AINeutralarXiv – CS AI · Mar 166/10
🧠A research study with 16 industry experts found that AI-assisted API design outperformed human-authored specifications in 10 of 11 usability dimensions while reducing authoring time by 87%. However, experts identified a 'Perfection Paradox' where AI-generated designs appeared unsettlingly perfect due to hyper-consistency, suggesting humans should shift from drafting to curating AI-generated patterns.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers propose Naïve PAINE, a lightweight system that improves text-to-image generation quality by predicting which initial noise inputs will produce better results before running the full diffusion model. The approach reduces the need for multiple generation cycles to get satisfactory images by pre-selecting higher-quality noise patterns.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers developed Q-DIG, a red-teaming method that uses Quality Diversity techniques to identify diverse language instruction failures in Vision-Language-Action models for robotics. The approach generates adversarial prompts that expose vulnerabilities in robot behavior and improves task success rates when used for fine-tuning.
AINeutralarXiv – CS AI · Mar 166/10
🧠Research reveals that large language models used as judges for scoring responses show misleading performance when evaluated by global correlation metrics versus actual best-of-n selection tasks. A study using 5,000 prompts found that judges with moderate global correlation (r=0.47) only captured 21% of potential improvement, primarily due to poor within-prompt ranking despite decent overall agreement.
AINeutralarXiv – CS AI · Mar 166/10
🧠Researchers have launched LLM BiasScope, an open-source web application that enables real-time bias analysis and side-by-side comparison of outputs from major language models including Google Gemini, DeepSeek, and Meta Llama. The platform uses a two-stage bias detection pipeline and provides interactive visualizations to help researchers and practitioners evaluate bias patterns across different AI models.
🏢 Hugging Face🧠 Gemini🧠 Llama
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers developed TERMINATOR, an early-exit strategy for Large Reasoning Models that reduces Chain-of-Thought reasoning lengths by 14-55% without performance loss. The system identifies optimal stopping points during inference to prevent overthinking and excessive compute usage.
AIBullisharXiv – CS AI · Mar 166/10
🧠Researchers propose Swap-guided Preference Learning (SPL) to address posterior collapse issues in Variational Preference Learning for RLHF systems. SPL introduces three new components to better capture personalized user preferences and improve AI alignment with diverse human values.