AINeutralCrypto Briefing · Jun 197/10
🧠CPUs are resurging as viable alternatives for AI inference tasks, challenging Nvidia's entrenched GPU dominance in the semiconductor market. This competitive shift could fundamentally reshape the AI chip landscape and create opportunities for traditional chipmakers to capture market share from Nvidia's historically dominant position.
🏢 Nvidia
AIBullishTechCrunch – AI · Jun 187/10
🧠Baseten, an AI inference startup, is reportedly closing a $1.5 billion funding round at a $13 billion valuation, capitalizing on surging demand for AI model inference capabilities. This mega-round follows the company's previous major funding and reflects intense investor competition in the AI infrastructure space.
AIBullisharXiv – CS AI · Jun 97/10
🧠Researchers propose S3, a training-free framework using Monte Carlo Tree Search to summarize long meeting documents by composing segment-level summaries. The approach achieves performance comparable to larger language models while using a 7B parameter model, addressing cumulative error propagation issues in multi-stage summarization pipelines.
AIBullisharXiv – CS AI · Jun 87/10
🧠OffQ introduces a novel quantization technique for large language models that addresses activation outliers through an offsetting mechanism, enabling efficient W4A4KV4 low-bit quantization. The method uses top-1 PCA to identify outlier subspaces and concentrates high-magnitude activations into a single channel via rotation, then converts this into a shared offset to reduce standard deviation. This approach maintains uniform-grid quantization while improving accuracy across diverse LLM architectures.
AIBullishCrypto Briefing · Jun 17/10
🧠Nvidia CEO Jensen Huang announced the production timeline for the Vera Rubin platform at GTC Taipei 2026, a chip architecture designed to significantly reduce AI inference costs. The platform could reshape economics in the AI industry by lowering computational expenses and altering market expectations for AI deployment.
🏢 Nvidia
AI × CryptoBullishBankless · May 287/10
🤖Eigen Labs launched Darkbloom, a system that converts idle Apple Silicon Macs into a distributed private inference network for AI processing. This development addresses computational bottlenecks in AI inference while enabling hardware owners to monetize underutilized devices.
AI × CryptoBullishCrypto Briefing · May 277/10
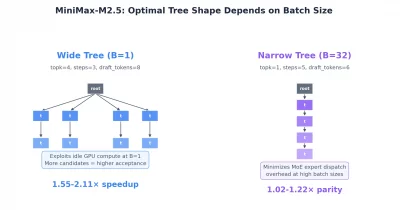
🤖MiniMax has announced its M3 model featuring a 15.6x faster decoding speed compared to previous versions, potentially reducing latency and operational costs for decentralized AI applications. This advancement could enhance scalability and efficiency across AI infrastructure, making decentralized AI systems more practical and cost-effective for broader adoption.
AI × CryptoBullishBankless · May 237/10
🤖Venice AI applies cypherpunk principles to artificial intelligence inference, building privacy protections into AI systems rather than treating it as an afterthought. The project draws philosophical parallels to the cypherpunk movement's core belief that privacy must be architecturally embedded, not granted by benevolent actors.
AIBullishHugging Face Blog · May 237/10
🧠NVIDIA's Nemotron-Labs team has developed diffusion-based language models that significantly accelerate text generation speeds, approaching real-time inference capabilities. This advancement combines diffusion model efficiency with language understanding, potentially reshaping how AI systems balance quality and computational cost.
AI × CryptoBullishBankless · May 157/10
🤖Cerebras' IPO signals a fundamental market shift from AI model training to inference optimization. Venice's ecosystem, featuring tokens like DIEM and POD, is positioned to capitalize on this transition as demand for efficient inference infrastructure grows.
AIBullisharXiv – CS AI · Apr 147/10
🧠Researchers introduce Introspective Diffusion Language Models (I-DLM), a new approach that combines the parallel generation speed of diffusion models with the quality of autoregressive models by ensuring models verify their own outputs. I-DLM achieves performance matching conventional large language models while delivering 3x higher throughput, potentially reshaping how AI systems are deployed at scale.
AIBullisharXiv – CS AI · Mar 177/10
🧠Researchers have discovered that large AI models develop decomposable internal structures during training, with many parameter dependencies remaining statistically unchanged from initialization. They propose a post-training method to identify and remove unsupported dependencies, enabling parallel inference without modifying model functionality.
AIBullishIEEE Spectrum – AI · Mar 167/10
🧠Nvidia announced the Groq 3 LPU at GTC 2024, its first chip specifically designed for AI inference rather than training, incorporating technology licensed from startup Groq for $20 billion. The chip uses SRAM memory integrated within the processor to achieve 7x faster memory bandwidth than traditional GPUs, optimizing for the low latency required for real-time AI inference applications.
🏢 Nvidia
AIBullisharXiv – CS AI · Mar 57/10
🧠Researchers introduce the Probability Navigation Architecture (PNA) framework that trains State Space Models with thermodynamic principles, discovering that SSMs develop 'architectural proprioception' - the ability to predict when to stop computation based on internal state entropy. This breakthrough shows SSMs can achieve computational self-awareness while Transformers cannot, with significant implications for efficient AI inference systems.
AIBullisharXiv – CS AI · Mar 56/10
🧠Researchers developed NRR-Phi, a framework that prevents large language models from prematurely committing to single interpretations of ambiguous text. The system maintains multiple valid interpretations in a non-collapsing state space, achieving 1.087 bits of mean entropy compared to zero for traditional collapse-based models.
AIBullisharXiv – CS AI · Mar 46/103
🧠Researchers propose a heterogeneous computing framework for Mixture-of-Experts AI models that combines analog in-memory computing with digital processing to improve energy efficiency. The approach identifies noise-sensitive experts for digital computation while running the majority on analog hardware, eliminating the need for costly retraining of large models.
AIBullisharXiv – CS AI · Mar 37/104
🧠Researchers have developed Hierarchical Speculative Decoding (HSD), a new method that significantly improves AI inference speed while maintaining accuracy by solving joint intractability problems in verification processes. The technique shows over 12% performance gains when integrated with existing frameworks like EAGLE-3, establishing new state-of-the-art efficiency standards.
AIBullishSimon Willison Blog · Jun 226/10
🧠Developers have successfully ported the Moebius 0.2B image inpainting model to run directly in web browsers using Claude Code, eliminating the need for server-side processing. This advancement demonstrates growing progress in deploying sophisticated AI models client-side, enhancing privacy and reducing infrastructure costs for AI applications.
🧠 Claude
AIBullishDecrypt – AI · Jun 106/10
🧠Google's DiffusionGemma AI model achieves 1,000 tokens per second by abandoning traditional word-by-word generation, offering free access but requiring substantial hardware that most users lack. This represents a significant speed breakthrough in AI inference, though practical adoption faces deployment barriers.
AIBullishCrypto Briefing · Jun 106/10
🧠DiffusionGemma, a new AI model, achieves 4x faster text generation through simultaneous token processing, potentially reducing computational costs and improving efficiency across industries dependent on language AI applications.
AI × CryptoBullishBlockonomi · Jun 16/10
🤖Tether has integrated Google's TurboQuant technology into production, enabling AI models to compress memory usage by up to 5x while maintaining quality. This advancement allows consumer devices like laptops and phones to run extended AI sessions locally without cloud reliance, advancing privacy-focused and efficient AI inference.
AI × CryptoBullishCrypto Briefing · Jun 16/10
🤖Tether is hiring inference engineers to advance local AI projects, signaling the cryptocurrency company's strategic pivot toward on-device AI solutions. This move positions Tether to leverage blockchain technology for enhanced data privacy in AI applications, potentially creating new cryptocurrency utility cases beyond trading and financial services.
AIBullisharXiv – CS AI · May 116/10
🧠Researchers propose VecCISC, an optimization framework for weighted majority voting in large language models that reduces computational costs by 47% while maintaining accuracy. The method filters redundant or hallucinated reasoning traces using semantic similarity before evaluation, addressing the expensive overhead of confidence-scoring multiple candidate answers.
AIBullishDecrypt – AI · May 76/10
🧠Google has developed Multi-Token Prediction drafters that accelerate Gemma 4 inference by up to 3x on local hardware without requiring cloud infrastructure or sacrificing output quality. This advancement makes efficient on-device AI more practical for developers and users seeking faster, privacy-preserving language model performance.
AINeutralarXiv – CS AI · May 16/10
🧠Researchers present a framework for optimizing AI inference workload placement across geographically distributed data centers by treating computation as relocatable electricity demand. The model balances latency constraints against energy costs and carbon intensity, revealing that workload flexibility significantly expands execution geography but faces practical friction from migration costs, regulatory limits, and network constraints.