AIBullishHugging Face Blog · Sep 257/105
🧠Meta has released Llama 3.2, introducing vision capabilities that allow the AI model to process and understand images alongside text. The update also enables the model to run locally on devices, providing enhanced privacy and offline functionality for users.
AIBullishOpenAI News · Sep 127/107
🧠OpenAI has announced the release of o1, a new AI model that represents a significant advancement in artificial intelligence capabilities. This launch marks another milestone in OpenAI's continued development of cutting-edge AI technology.
AIBullishOpenAI News · Sep 127/106
🧠OpenAI has introduced o1, a new large language model that uses reinforcement learning to perform complex reasoning tasks. The model generates an internal chain of thought before providing responses, representing a significant advancement in AI reasoning capabilities.
AIBullishOpenAI News · May 137/103
🧠OpenAI is launching GPT-4o as their newest flagship model and making more capabilities available to free ChatGPT users. This represents a significant expansion of free access to advanced AI tools.
AIBullishOpenAI News · May 137/104
🧠OpenAI announces the release of GPT-4o and expands free access to more ChatGPT capabilities. This spring update represents a significant advancement in AI accessibility and functionality.
AIBullishOpenAI News · Mar 147/107
🧠OpenAI has released GPT-4, a major advancement in their deep learning efforts that represents a multimodal AI model capable of processing both image and text inputs while generating text outputs. The model demonstrates human-level performance on various professional and academic benchmarks, though it still falls short of human capabilities in many real-world applications.
AIBullishOpenAI News · Nov 307/107
🧠OpenAI has introduced ChatGPT, a conversational AI model designed to interact through dialogue. The model can answer follow-up questions, admit mistakes, challenge incorrect premises, and reject inappropriate requests.
AIBullishCrypto Briefing · Jun 236/10
🧠Mistral AI has launched OCR 4, an optical character recognition model achieving a 72% win rate against competitors in blind tests while supporting 170 languages. The technology targets the document processing market with competitive accuracy and flexible deployment options, positioning itself as a disruptor against established incumbents.
🏢 Mistral
AINeutralDecrypt – AI · Apr 186/10
🧠OpenAI has released GPT-Rosalind, a specialized AI model designed specifically for drug discovery and life sciences applications that can significantly accelerate research timelines. However, the model's access is restricted and not available to the general public, limiting its immediate impact to institutional researchers and pharmaceutical companies.
🏢 OpenAI
AIBullisharXiv – CS AI · Mar 276/10
🧠Voxtral TTS is a new multilingual text-to-speech AI model that can generate natural speech from just 3 seconds of reference audio. In human evaluations, it achieved a 68.4% win rate over ElevenLabs Flash v2.5 for voice cloning, demonstrating superior naturalness and expressivity.
AIBullishMarkTechPost · Mar 266/10
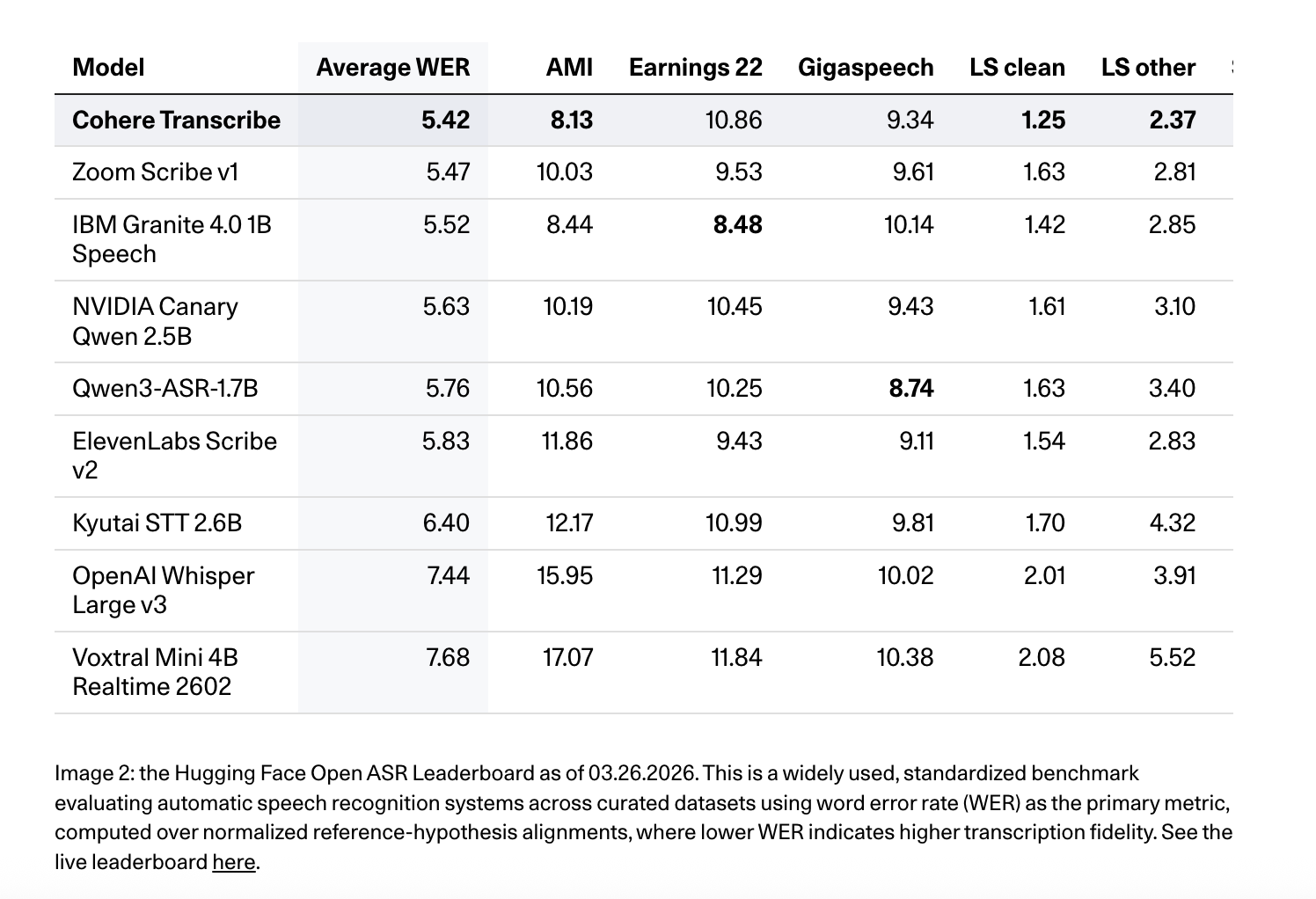
🧠Cohere AI has released Cohere Transcribe, a new state-of-the-art Automatic Speech Recognition (ASR) model designed for enterprise applications. This marks the company's expansion beyond text generation and embedding models into the speech recognition market, targeting enterprise speech intelligence solutions.
🏢 Cohere
AIBullishMarkTechPost · Mar 156/10
🧠Zhipu AI has released GLM-OCR, a compact 0.9B parameter multimodal model designed to solve real-world document parsing challenges including OCR, table extraction, formula recognition, and key information extraction. The model aims to address the engineering difficulties of processing actual documents rather than clean demo images while maintaining resource efficiency.
AIBullishCrypto Briefing · Mar 36/101
🧠Google has launched Gemini 3.1 Flash Lite, positioning it as the fastest and most cost-effective model in the Gemini 3 series. The new AI model targets developers with enhanced speed performance, improved benchmarks, and scalable API pricing structure.
AIBullishGoogle DeepMind Blog · Mar 36/104
🧠Google has announced Gemini 3.1 Flash-Lite, positioning it as the fastest and most cost-efficient model in their Gemini 3 series. The model appears designed for large-scale deployment with optimized performance and reduced operational costs.
AIBullisharXiv – CS AI · Mar 27/1014
🧠VoiceBridge is a new AI model that can restore high-quality 48kHz speech from various types of audio distortions using a single one-step process. The model uses a latent bridge approach with an energy-preserving variational autoencoder and transformer architecture to handle multiple speech restoration tasks simultaneously.
AIBullishGoogle DeepMind Blog · Feb 265/107
🧠Nano Banana 2 is a new image generation model that combines advanced capabilities including world knowledge, production-ready specifications, and subject consistency while maintaining Flash-level speed. The model represents an advancement in AI image generation technology by offering professional-grade features without sacrificing performance.
AIBullishTechCrunch – AI · Feb 266/103
🧠Google has launched Nano Banana 2, a new AI model featuring faster image generation capabilities. The model is being integrated as the default in Google's Gemini app and AI mode, representing a significant update to Google's AI infrastructure.
AIBullishGoogle DeepMind Blog · Feb 196/107
🧠Google has announced Gemini 3.1 Pro, a new AI model specifically designed to handle complex tasks that require more sophisticated reasoning than simple question-and-answer scenarios. The model represents an advancement in AI capabilities for demanding computational and analytical work.
AINeutralOpenAI News · Dec 116/105
🧠OpenAI has released GPT-5.2, the latest model in the GPT-5 series, maintaining the same comprehensive safety mitigation approach as previous versions. The model was trained on diverse datasets including publicly available internet information, third-party partnerships, and user-generated content.
AIBullishGoogle DeepMind Blog · Oct 256/107
🧠Google has released Gemini 2.5 Flash-Lite as a stable, generally available model after its preview phase. The cost-efficient AI model offers high quality performance in a compact size, featuring a 1 million-token context window and multimodal capabilities.
AIBullishGoogle DeepMind Blog · Oct 236/108
🧠Google has released Gemma 3 270M, a compact AI model with 270 million parameters designed for hyper-efficient artificial intelligence applications. This new addition to the Gemma 3 toolkit represents a specialized tool focused on delivering AI capabilities in a smaller, more resource-efficient package.
AIBullishHugging Face Blog · Jun 36/106
🧠SmolVLA is a new efficient vision-language-action model that has been trained using data from the Lerobot community. This represents an advancement in AI models that can process visual and language inputs to generate actions, potentially improving robotic and automation applications.
AIBullishSynced Review · Apr 306/106
🧠DeepSeek AI has released DeepSeek-Prover-V2, an open-source large language model specifically designed for Lean 4 theorem proving. The model employs recursive proof search methodology and uses DeepSeek-V3 for training data generation with reinforcement learning, achieving top performance results on the MiniF2F benchmark.
AIBullishGoogle DeepMind Blog · Mar 126/105
🧠Google has announced Gemma 3, positioning it as their most capable AI model that can run on a single GPU or TPU. This represents a significant advancement in making powerful AI models more accessible for individual developers and smaller organizations.
AIBullishHugging Face Blog · Mar 126/107
🧠Google has announced Gemma 3, their latest open-source large language model featuring multimodal capabilities, multilingual support, and extended context length. The article title suggests this represents a significant advancement in Google's open LLM offerings, though specific technical details and capabilities are not provided in the given content.