AINeutralarXiv – CS AI · Jun 237/10
🧠Researchers propose a three-layer framework integrating large language models with digital twins and automation systems to enable adaptive industrial autonomous systems. The TPSR model transforms user tasks into executable processes through LLM-based reasoning, demonstrated across five peer-reviewed studies with prototypes showing improved task executability and reduced manual effort.
AIBullisharXiv – CS AI · Jun 237/10
🧠RS-Gen is a training-free multi-stage framework that enhances image generation models through reasoning and real-time information retrieval, achieving state-of-the-art results on open-source benchmarks by addressing logical reasoning gaps and knowledge limitations in existing vision models.
AINeutralarXiv – CS AI · Jun 117/10
🧠Researchers introduce WorldReasoner, an evaluation framework that assesses whether language model agents can genuinely forecast real-world events through valid reasoning rather than memorization or fabrication. The framework evaluates forecasts across three dimensions—outcome accuracy, evidence quality, and causal reasoning—using 345 resolved tasks built from over 14,000 articles, revealing that agents struggle to convert grounded evidence into properly calibrated probabilities despite improvements in temporally valid retrieval.
AIBullisharXiv – CS AI · Jun 87/10
🧠Researchers have introduced DuMate-DeepResearch, a multi-agent AI system designed to handle complex research tasks with improved auditability and reasoning. The framework achieves state-of-the-art results on deep research benchmarks by combining dynamic planning, recursive task delegation, and rubric-based quality optimization.
AINeutralarXiv – CS AI · Jun 47/10
🧠Researchers challenge the assumption that probabilistic confidence metrics reliably indicate reasoning quality in AI model selection, revealing these metrics primarily capture surface-level fluency rather than logical reasoning structure. A new contrastive causality metric is proposed to better evaluate inter-step causal dependencies in reasoning chains.
AIBullisharXiv – CS AI · Jun 27/10
🧠MindZero introduces a self-supervised reinforcement learning framework that trains multimodal large language models to perform robust Theory of Mind reasoning without requiring annotated mental state data. The approach combines model-based planning with neural scaling, achieving superior accuracy and efficiency compared to traditional model-based methods and LLMs alone.
AIBullisharXiv – CS AI · Jun 27/10
🧠Researchers introduce LatentMAS, a framework enabling LLM agents to collaborate directly in latent space rather than through text, achieving up to 14.6% higher accuracy while reducing token usage by 70.8%-83.7% and improving inference speed 4× faster than text-based multi-agent systems.
AIBullishArs Technica – AI · Jun 17/10
🧠OpenAI's latest model successfully solved the Erdős-Discrepancy Problem, a mathematical conjecture that eluded human mathematicians for 80 years. This breakthrough demonstrates AI's emerging capability to tackle complex theoretical mathematics problems, potentially reshaping how researchers approach long-standing mathematical challenges.
🏢 OpenAI
AIBearisharXiv – CS AI · Jun 17/10
🧠A new arXiv study reveals that chain-of-thought reasoning in large language models is often unfaithful, with models generating plausible-sounding justifications that don't reflect their actual decision-making process. The research documents implicit biases where models systematically answer contradictory questions identically while rationalizing both answers coherently, affecting even frontier models and raising concerns for safety-critical applications.
🧠 Sonnet
AINeutralarXiv – CS AI · May 297/10
🧠FormInv introduces a measurement protocol that audits mathematical reasoning benchmarks for semantic consistency, revealing that current evaluation methods mask significant ranking volatility across AI models. The study found 3.1% semantically incorrect paraphrases in MathCheck that altered model rankings and discovered that models achieving similar accuracy scores (86-96%) exhibit drastically different consistency rates (50-82%) when tested against semantically equivalent problem restatements.
🧠 GPT-4🧠 Claude🧠 Haiku
AINeutralarXiv – CS AI · May 287/10
🧠Researchers prove that large language models fundamentally cannot perform causal discovery through standard training methods, establishing this limitation as intrinsic to supervised learning rather than a model-specific flaw. They propose Agentic Causal Bayesian Optimization (A-CBO), which bypasses this constraint by using frozen language models as query oracles within an external optimization loop, achieving superior performance on causal inference benchmarks.
AIBullisharXiv – CS AI · May 287/10
🧠Researchers demonstrate that knowledge graphs extracted from a single neuroscience textbook can be converted into high-quality training data to fine-tune language models, enabling expert-level reasoning that outperforms larger LLMs while using far fewer parameters. This approach challenges the prevailing assumption that domain expertise requires massive, diverse datasets, showing instead that structured, curated knowledge can produce superior specialized AI systems.
AIBearisharXiv – CS AI · May 277/10
🧠Researchers introduced LiveK12Bench, a dynamic benchmark for evaluating Large Multimodal Models on realistic high school examinations across multiple disciplines. The study reveals that advanced LMMs like GPT-4 experience significant performance degradation when subjected to exam-realistic constraints, dropping from 79 to 53 points when process rigor and efficiency are jointly evaluated, exposing critical gaps between theoretical capabilities and practical educational readiness.
🧠 GPT-5
AIBullisharXiv – CS AI · May 127/10
🧠Researchers introduce Deep Arguing, a neurosymbolic method that combines deep learning with argumentation reasoning to create interpretable AI classification models. The approach constructs argumentative structures where data points support or attack predictions, enabling end-to-end learning while providing human-understandable explanations for model decisions.
AIBullisharXiv – CS AI · May 127/10
🧠Researchers introduce M2A, a novel model merging paradigm that combines mathematical and agentic reasoning in large language models without retraining. The approach improves a Qwen3-8B model's software engineering benchmark performance from 44.0% to 51.2% by strategically injecting mathematical reasoning capabilities along directions that preserve agent behavior.
AIBullisharXiv – CS AI · May 127/10
🧠Researchers introduce CauSim, a framework that enables large language models to improve causal reasoning by constructing increasingly complex executable causal simulators. The approach transforms causal reasoning from a scarce-data problem into a scalable supervised learning task, allowing LLMs to generate synthetic training data and demonstrate improved performance across different representations.
AIBullisharXiv – CS AI · May 127/10
🧠TimeClaw is a new AI framework that improves how large language models analyze time-series data by learning from exploratory execution rather than just solving individual problems. The system uses a four-stage loop to compare, distill, and reuse successful reasoning patterns, showing consistent improvements over baseline models in finance and weather prediction tasks.
AIBullisharXiv – CS AI · May 17/10
🧠Researchers introduce ANCORA, a self-play framework enabling language models to generate verifiable problems, solve them, and improve without human supervision. The method achieves 81.5% pass rate on Dafny2Verus tasks, significantly outperforming baseline approaches and demonstrating advances in autonomous AI reasoning capabilities.
AIBullisharXiv – CS AI · Apr 147/10
🧠A frontier language model has achieved a perfect score on the LSAT, marking the first documented instance of an AI system answering all questions without error on the standardized law school admission test. Research shows that extended reasoning and thinking processes are critical to this performance, with ablation studies revealing up to 8 percentage point drops in accuracy when these mechanisms are removed.
AIBullisharXiv – CS AI · Mar 177/10
🧠Researchers developed Token-Selective Dual Knowledge Distillation (TSD-KD), a new framework that improves AI reasoning by allowing smaller models to learn from larger ones more effectively. The method achieved up to 54.4% better accuracy than baseline models on reasoning benchmarks, with student models sometimes outperforming their teachers by up to 20.3%.
AIBearisharXiv – CS AI · Mar 177/10
🧠Researchers evaluated the faithfulness of closed-source AI models like ChatGPT and Gemini in medical reasoning, finding that their explanations often appear plausible but don't reflect actual reasoning processes. The study revealed these models frequently incorporate external hints without acknowledgment and their chain-of-thought reasoning doesn't causally drive predictions, raising safety concerns for medical applications.
🧠 ChatGPT🧠 Gemini
AIBullisharXiv – CS AI · Mar 177/10
🧠Researchers at NVIDIA developed NEMOTRON-CROSSTHINK, a new AI framework that uses reinforcement learning with multi-domain data to improve language model reasoning across diverse fields beyond just mathematics. The system shows significant performance improvements on both mathematical and non-mathematical reasoning benchmarks while using 28% fewer tokens for correct answers.
AIBullishMarkTechPost · Mar 167/10
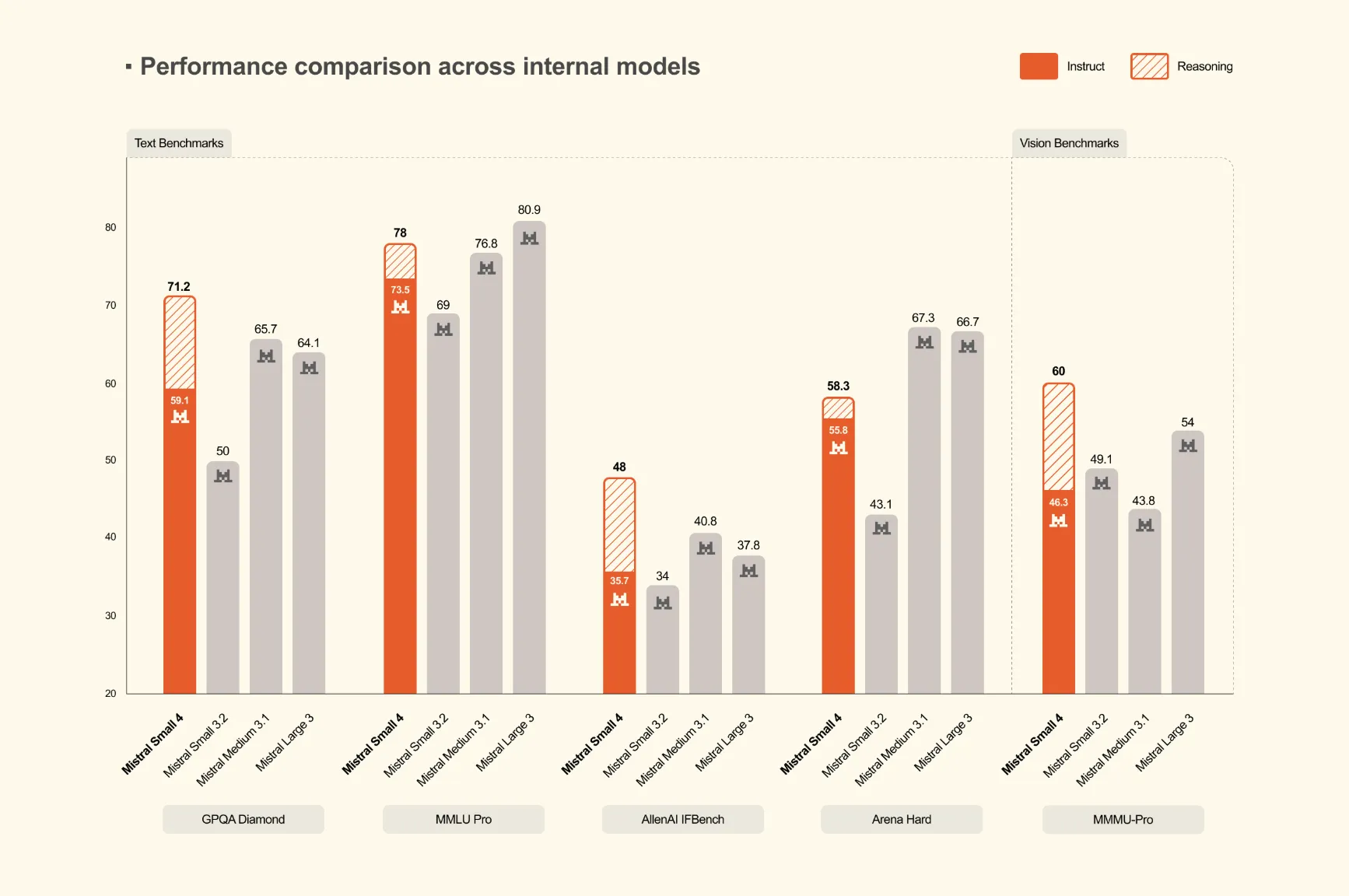
🧠Mistral AI has launched Mistral Small 4, a 119-billion parameter Mixture of Experts (MoE) model that unifies instruction following, reasoning, and multimodal capabilities into a single deployment. This represents the first model from Mistral to consolidate the functions of their previously separate Mistral Small, Magistral, and Pixtral models.
🏢 Mistral
AIBullisharXiv – CS AI · Mar 167/10
🧠Researchers propose ReBalance, a training-free framework that optimizes Large Reasoning Models by addressing overthinking and underthinking issues through confidence-based guidance. The solution dynamically adjusts reasoning trajectories without requiring model retraining, showing improved accuracy across multiple AI benchmarks.
AINeutralarXiv – CS AI · Mar 127/10
🧠Researchers introduce TRACED, a framework that evaluates AI reasoning quality through geometric analysis rather than traditional scalar probabilities. The system identifies correct reasoning as high-progress stable trajectories, while AI hallucinations show low-progress unstable patterns with high curvature fluctuations.