AIBullisharXiv – CS AI · Jun 107/10
🧠Whisfusion introduces a masked diffusion decoder that achieves faster speech-to-text processing than Whisper-large-v3 while matching or exceeding its accuracy across multilingual benchmarks. By replacing autoregressive decoding with parallel diffusion decoding, the system runs 4-5x faster while maintaining competitive performance with leading ASR systems, establishing non-autoregressive diffusion as a viable paradigm for high-throughput transcription.
AIBullisharXiv – CS AI · May 127/10
🧠Researchers introduce WorldSpeech, a multilingual speech corpus containing 65,000 hours of aligned audio-transcript data across 76 languages, addressing the critical gap in ASR training data for low-resource languages. Fine-tuning existing ASR models on this dataset achieves an average 63.5% relative Word-Error-Rate reduction, significantly improving speech recognition accuracy for underrepresented languages.
AINeutralarXiv – CS AI · Jun 256/10
🧠Researchers propose SE-AGCNet, an end-to-end framework that jointly optimizes speech enhancement and automatic gain control for meeting scenarios. The approach addresses limitations of traditional discrete audio processing pipelines by leveraging synergy between the two tasks, improving speech quality, loudness consistency, and automatic speech recognition accuracy.
AIBullisharXiv – CS AI · Jun 256/10
🧠Researchers propose an error-aware TF-IDF retrieval-augmented generation framework that corrects automatic speech recognition (ASR) errors by using phonetically-aware lexical matching rather than heavy cross-modal embeddings. The method achieved a 37.2 percentage-point improvement in error-aware hit rate and reduced word error rate by 4.23 points on Persian speech data with minimal computational overhead.
AIBullisharXiv – CS AI · Jun 236/10
🧠Researchers successfully fine-tuned automatic speech recognition (ASR) models to create text corpora for low-resource African languages Fongbe and Hausa, achieving significant improvements in transcription accuracy. The work demonstrates ASR's potential for rapidly expanding language resources in underrepresented languages, though quality varies by linguistic complexity, with Hausa transcriptions approaching production-ready standards while Fongbe requires further refinement.
AINeutralarXiv – CS AI · Jun 196/10
🧠Researchers developed data augmentation techniques to improve automatic speech recognition (ASR) for people with dysarthria by fine-tuning the Wav2Vec2 model. Using methods like speaking-rate modification, pitch modification, and formant modification tailored to different severity levels, the study achieved significant word error rate reductions across low, medium, and high severity dysarthric speech.
AINeutralarXiv – CS AI · Jun 106/10
🧠Researchers introduce ELF-S2T, a novel continuous-target generative model for speech-to-text tasks that combines audio conditioning with diffusion-based language modeling. The approach achieves competitive performance on ASR and speech translation while revealing that both tasks share common error patterns rooted in continuous latent space representations.
AINeutralHugging Face Blog · Jun 96/10
🧠Researchers benchmark frontier automatic speech recognition (ASR) systems on code-switched speech, where bilingual speakers mix languages mid-conversation. The study evaluates how well modern voice AI handles this common real-world scenario, revealing performance gaps that matter for customer service applications.
AINeutralarXiv – CS AI · Jun 96/10
🧠Researchers present a rigorous study of fine-tuning OpenAI's Whisper model for Swiss German speech recognition, achieving 25.6% WER with honest evaluation on disjoint test data. The work exposes significant benchmark contamination in published Swiss German ASR results, revealing that previous state-of-the-art claims were inflated by models memorizing test sets rather than genuinely understanding dialect.
🏢 OpenAI🏢 Nvidia
AINeutralarXiv – CS AI · Jun 95/10
🧠Researchers propose a training-free method for improving automatic speech recognition in noisy environments by intelligently fusing noisy and speech-enhanced audio based on intelligibility estimates. The approach eliminates the need for trained neural predictors, reducing complexity while maintaining robustness across diverse speech enhancement and ASR model combinations.
AIBullishHugging Face Blog · Jun 46/10
🧠This article provides guidance on fine-tuning Nemotron 3.5 ASR, NVIDIA's automatic speech recognition model, to improve accuracy for specific languages, domains, and accents. The tutorial enables developers to customize the open-source model for specialized use cases beyond its default training data.
AIBullisharXiv – CS AI · Jun 26/10
🧠Researchers introduce Murmur, an inference system that optimizes long-form automatic speech recognition by balancing accuracy and latency through a two-level approach: intermediate chunk sizes at the inter-chunk level and attention sparsity exploitation at the intra-chunk level. The system achieves 4.2x latency reduction while maintaining single-pass accuracy on benchmark tests.
AIBullisharXiv – CS AI · May 296/10
🧠Researchers introduce Agentic ASR, a multi-turn interactive speech recognition framework that enables iterative refinement of recognized speech through semantic correction and reasoning-based editing. The approach addresses limitations of single-pass ASR systems by aligning with human communication patterns, introducing a new semantic evaluation metric (S²ER) that better captures meaning-critical errors than traditional token-level metrics.
AIBullisharXiv – CS AI · Apr 136/10
🧠Researchers propose Interactive ASR, a new framework that combines semantic-aware evaluation using LLM-as-a-Judge with multi-turn interactive correction to improve automatic speech recognition beyond traditional word error rate metrics. The approach simulates human-like interaction, enabling iterative refinement of recognition outputs across English, Chinese, and code-switching datasets.
AIBearisharXiv – CS AI · Mar 276/10
🧠Researchers introduced WildASR, a multilingual diagnostic benchmark revealing that current ASR systems suffer severe performance degradation in real-world conditions despite achieving near-human accuracy on curated tests. The study found that ASR models often hallucinate plausible but unspoken content under degraded inputs, creating safety risks for voice agents.
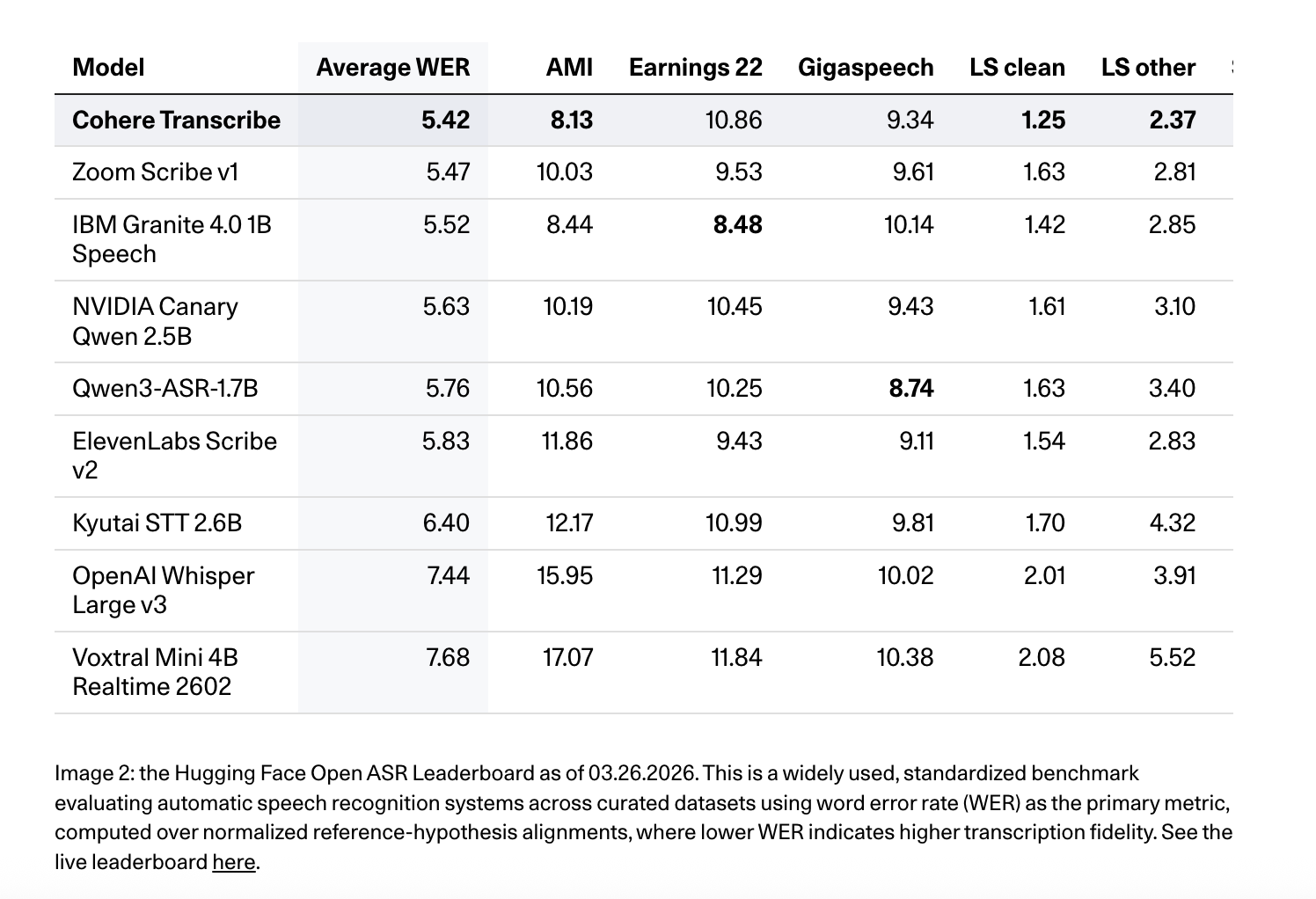
AIBullishMarkTechPost · Mar 266/10
🧠Cohere AI has released Cohere Transcribe, a new state-of-the-art Automatic Speech Recognition (ASR) model designed for enterprise applications. This marks the company's expansion beyond text generation and embedding models into the speech recognition market, targeting enterprise speech intelligence solutions.
🏢 Cohere
AIBullishMarkTechPost · Mar 176/10
🧠Google AI has released WAXAL, an open multilingual speech dataset covering 24 African languages to improve Automatic Speech Recognition and Text-to-Speech systems. This addresses the significant data distribution problem where African languages remain poorly represented in speech technology training corpora.
🏢 Google
AIBullishMarkTechPost · Mar 166/10
🧠IBM has released Granite 4.0 1B Speech, a compact multilingual speech-language model optimized for automatic speech recognition and translation. The model is specifically designed for enterprise and edge deployments where memory efficiency, low latency, and compute optimization are critical alongside performance quality.
AIBullisharXiv – CS AI · Mar 116/10
🧠DuplexCascade introduces a VAD-free cascaded streaming pipeline that enables full-duplex speech-to-speech dialogue while maintaining LLM intelligence. The system converts traditional long utterance turns into micro-turn interactions using special control tokens to coordinate turn-taking and response timing.
AIBullisharXiv – CS AI · Mar 116/10
🧠Facebook Research introduces the Latent Speech-Text Transformer (LST), which aggregates speech tokens into higher-level patches to improve computational efficiency and cross-modal alignment. The model achieves up to +6.5% absolute gain on speech HellaSwag benchmarks while maintaining text performance and reducing inference costs for ASR and TTS tasks.
AIBearisharXiv – CS AI · Mar 96/10
🧠Research reveals that speech LLMs don't perform significantly better than traditional ASR→LLM pipelines in most deployed scenarios. The study shows speech LLMs essentially function as expensive cascades that perform worse under noisy conditions, with advantages reversing by up to 7.6% at 0dB noise levels.
$LLM
AIBullisharXiv – CS AI · Mar 45/103
🧠Researchers developed GLoRIA, a parameter-efficient framework for automatic speech recognition that adapts to regional dialects using location metadata. The system achieves state-of-the-art performance while updating less than 10% of model parameters and demonstrates strong generalization to unseen dialects.
AIBullisharXiv – CS AI · Mar 37/107
🧠Researchers introduce Whisper-MLA, a modified version of OpenAI's Whisper speech recognition model that uses Multi-Head Latent Attention to reduce GPU memory consumption by up to 87.5% while maintaining accuracy. The innovation addresses a key scalability issue with transformer-based ASR models when processing long-form audio.
AIBullisharXiv – CS AI · Mar 26/1015
🧠Researchers developed Whisper-LLaDA, a diffusion-based large language model for automatic speech recognition that achieves 12.3% relative improvement over baseline models. The study demonstrates that audio-conditioned embeddings are crucial for accuracy improvements, while plain-text processing without acoustic features fails to enhance performance.
AIBullisharXiv – CS AI · Feb 276/107
🧠Researchers developed a new AI framework using RNN-T architecture to improve speech recognition for Taiwanese Hakka, an endangered low-resource language with high dialectal variability. The system achieved 57% and 40% relative error rate reductions for two different writing systems, marking the first systematic investigation into Hakka dialect variations in ASR.