#multimodal-ai News & Analysis
The #multimodal-ai tag covers 270 indexed articles, with 51 published in the last month. Recent discussion shows predominantly neutral sentiment at 58.8%, though bullish coverage has declined 25.5 percentage points compared to the prior quarter, signaling cooling enthusiasm. Research preprints dominate the conversation via arXiv, with models like Gemini and GPT-4 appearing frequently in related discussions.
Coverage clusters around machine learning, computer vision, and vision-language models as complementary topics. Scan the articles below to explore how multimodal systems are being developed and deployed across the industry.
sentiment · last 30d (51 articles) · -25.5pp bullish vs prior 90dTop sources:arXiv – CS AI · 228Apple Machine Learning · 2TechCrunch – AI · 2MarkTechPost · 1The Verge – AI · 1
Most-discussed entities:Gemini · 8GPT-4 · 5GPT-5 · 3Claude · 2Mistral · 1
AIBullisharXiv – CS AI · Mar 267/10
🧠Researchers developed SCoOP, a training-free framework that combines multiple Vision-Language Models to improve uncertainty quantification and reduce hallucinations in AI systems. The method achieves 10-13% better hallucination detection performance compared to existing approaches while adding only microsecond-level overhead to processing time.
AIBullisharXiv – CS AI · Mar 267/10
🧠Researchers developed Attention Imbalance Rectification (AIR), a method to reduce object hallucinations in Large Vision-Language Models by correcting imbalanced attention allocation between vision and language modalities. The technique achieves up to 35.1% reduction in hallucination rates while improving general AI capabilities by up to 15.9%.
AIBearisharXiv – CS AI · Mar 177/10
🧠Research reveals that fine-tuning aligned vision-language AI models on narrow harmful datasets causes severe safety degradation that generalizes across unrelated tasks. The study shows multimodal models exhibit 70% higher misalignment than text-only evaluation suggests, with even 10% harmful training data causing substantial alignment loss.
AIBullisharXiv – CS AI · Mar 177/10
🧠Researchers have extended the RESTA defense mechanism to vision-language models (VLMs) to protect against jailbreaking attacks that can cause AI systems to produce harmful outputs. The study found that directional embedding noise significantly reduces attack success rates across the JailBreakV-28K benchmark, providing a lightweight security layer for AI agent systems.
AINeutralarXiv – CS AI · Mar 177/10
🧠Researchers introduced VideoSafetyEval, a benchmark revealing that video-based large language models have 34.2% worse safety performance than image-based models. They developed VideoSafety-R1, a dual-stage framework that achieves 71.1% improvement in safety through alarm token-guided fine-tuning and safety-guided reinforcement learning.
AIBullisharXiv – CS AI · Mar 177/10
🧠Researchers developed AD-Copilot, a specialized multimodal AI assistant for industrial anomaly detection that outperforms existing models and even human experts. The system uses a novel visual comparison approach and achieved 82.3% accuracy on benchmarks, representing up to 3.35x improvement over baselines.
🏢 Microsoft
AIBullisharXiv – CS AI · Mar 177/10
🧠Researchers have developed UniVid, a new pyramid diffusion model that unifies text-to-video and image-to-video generation into a single system. The model uses dual-stream cross-attention mechanisms to process both text prompts and reference images, achieving superior temporal coherence across different video generation tasks.
AIBullishMarkTechPost · Mar 167/10
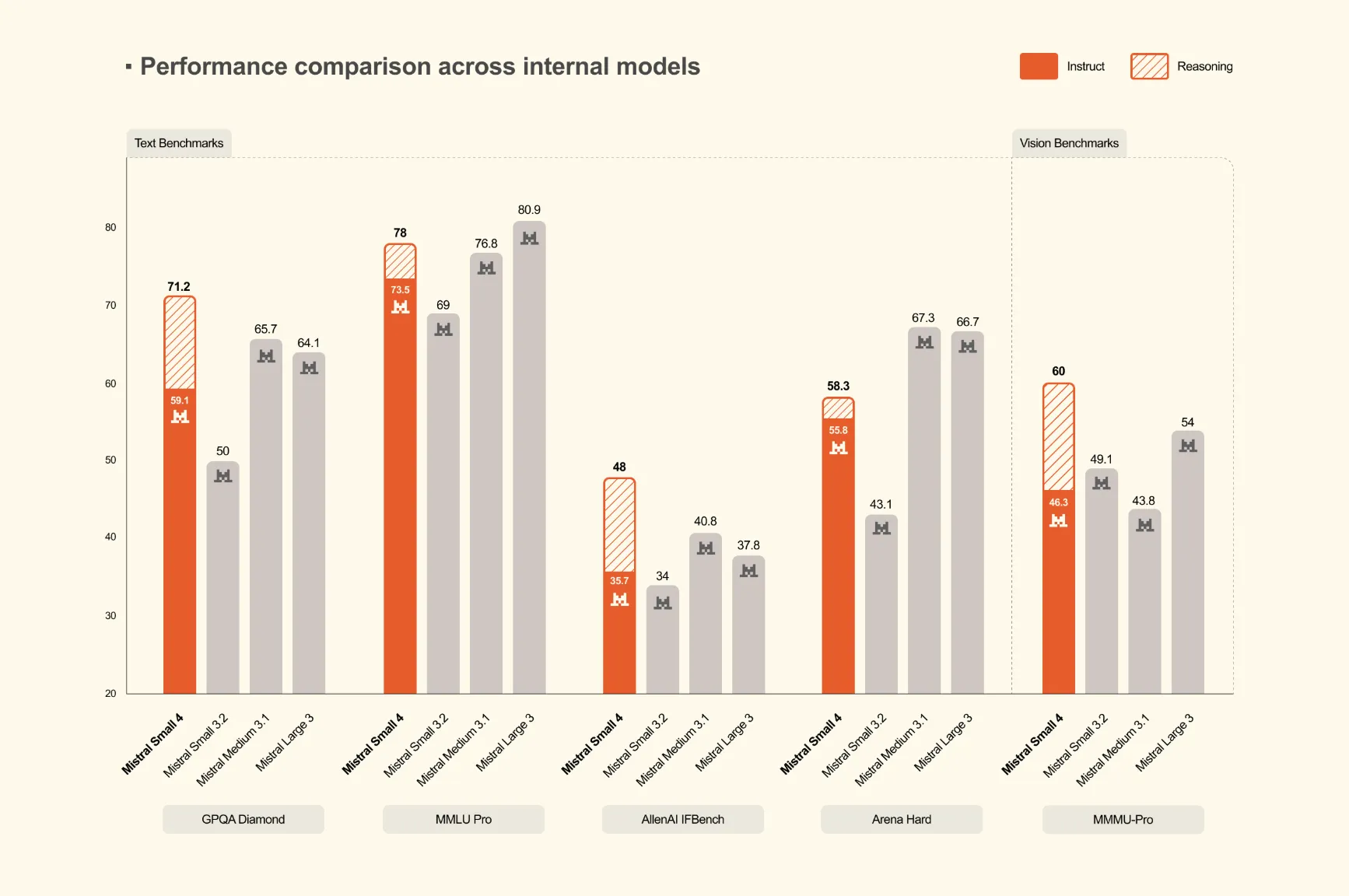
🧠Mistral AI has launched Mistral Small 4, a 119-billion parameter Mixture of Experts (MoE) model that unifies instruction following, reasoning, and multimodal capabilities into a single deployment. This represents the first model from Mistral to consolidate the functions of their previously separate Mistral Small, Magistral, and Pixtral models.
🏢 Mistral
AIBullisharXiv – CS AI · Mar 167/10
🧠Researchers introduce improved methods for stitching Vision Foundation Models (VFMs) like CLIP and DINOv2, enabling integration of different models' strengths. The study proposes VFM Stitch Tree (VST) technique that allows controllable accuracy-latency trade-offs for multimodal applications.
AIBullisharXiv – CS AI · Mar 117/10
🧠Researchers introduce World2Mind, a training-free spatial intelligence toolkit that enhances foundation models' 3D spatial reasoning capabilities by up to 18%. The system uses 3D reconstruction and cognitive mapping to create structured spatial representations, enabling text-only models to perform complex spatial reasoning tasks.
🧠 GPT-5
AIBearisharXiv – CS AI · Mar 67/10
🧠Researchers discovered a new vulnerability in multimodal large language models where specially crafted images can cause significant performance degradation by inducing numerical instability during inference. The attack method was validated on major vision-language models including LLaVa, Idefics3, and SmolVLM, showing substantial performance drops even with minimal image modifications.
AIBullishTechCrunch – AI · Mar 57/10
🧠Luma has launched Luma Agents, a new creative AI platform powered by 'Unified Intelligence' models that can coordinate multiple AI systems to generate comprehensive creative work across text, images, video, and audio. This represents a significant advancement in multimodal AI capabilities for creative applications.
AIBullisharXiv – CS AI · Mar 56/10
🧠Researchers developed LiteVLA-Edge, a deployment-oriented Vision-Language-Action model pipeline that enables fully on-device inference on embedded robotics hardware like Jetson Orin. The system achieves 150.5ms latency (6.6Hz) through FP32 fine-tuning combined with 4-bit quantization and GPU-accelerated inference, operating entirely offline within a ROS 2 framework.
AIBearisharXiv – CS AI · Mar 57/10
🧠Researchers have developed Image-based Prompt Injection (IPI), a black-box attack that embeds adversarial instructions into natural images to manipulate multimodal AI models. Testing on GPT-4-turbo achieved up to 64% attack success rate, demonstrating a significant security vulnerability in vision-language AI systems.
🧠 GPT-4
AIBullisharXiv – CS AI · Mar 57/10
🧠Researchers released Phi-4-reasoning-vision-15B, a compact open-weight multimodal AI model that combines vision and language capabilities with strong performance in scientific and mathematical reasoning. The model demonstrates that careful architecture design and high-quality data curation can enable smaller models to achieve competitive performance with less computational resources.
AIBullisharXiv – CS AI · Mar 56/10
🧠Researchers successfully developed multimodal large language models for Basque, a low-resource language, finding that only 20% Basque training data is needed for solid performance. The study demonstrates that specialized Basque language backbones aren't required, potentially enabling MLLM development for other underrepresented languages.
🧠 Llama
AIBullisharXiv – CS AI · Mar 56/10
🧠GIPO (Gaussian Importance Sampling Policy Optimization) is a new reinforcement learning method that improves data efficiency for training multimodal AI agents. The approach uses Gaussian trust weights instead of hard clipping to better handle scarce or outdated training data, showing superior performance and stability across various experimental conditions.
AIBullisharXiv – CS AI · Mar 57/10
🧠Researchers introduce Visual Attention Score (VAS) to analyze multimodal reasoning models, discovering that higher visual attention correlates strongly with better performance (r=0.9616). They propose AVAR framework that achieves 7% performance gains on Qwen2.5-VL-7B across multimodal reasoning benchmarks.
AIBullisharXiv – CS AI · Mar 56/10
🧠PRAM-R introduces a new AI framework for autonomous driving that uses LLM-guided modality routing to adaptively select sensors based on environmental conditions. The system achieves 6.22% modality reduction while maintaining trajectory accuracy, demonstrating efficient resource management in multimodal perception systems.
AIBullisharXiv – CS AI · Mar 56/10
🧠Researchers propose PROSPECT, a new AI system that combines semantic understanding with spatial modeling for improved Vision-Language Navigation. The system uses streaming 3D spatial encoding and predictive representation learning to achieve state-of-the-art performance in robot navigation tasks.
AIBullisharXiv – CS AI · Mar 56/10
🧠Researchers developed EvoPrune, a new method that prunes visual tokens during the encoding stage of Multimodal Large Language Models (MLLMs) rather than after encoding. The technique achieves 2x inference speedup with less than 1% performance loss on video datasets, addressing efficiency bottlenecks in AI models processing high-resolution images and videos.
AIBullisharXiv – CS AI · Mar 56/10
🧠Researchers introduced PulseLM, a large-scale dataset combining PPG cardiovascular sensor data with natural language processing for multimodal AI models. The dataset contains 1.31 million PPG segments with 3.15 million question-answer pairs, designed to enable language-based physiological reasoning in healthcare AI applications.
AIBullisharXiv – CS AI · Mar 57/10
🧠Researchers introduce Vision-Zero, a self-improving AI framework that trains vision-language models through competitive games without requiring human-labeled data. The system uses strategic self-play and can work with arbitrary images, achieving state-of-the-art performance on reasoning and visual understanding tasks while reducing training costs.
AINeutralarXiv – CS AI · Mar 57/10
🧠Researchers introduced InEdit-Bench, the first evaluation benchmark specifically designed to test image editing models' ability to reason through intermediate logical pathways in multi-step visual transformations. Testing 14 representative models revealed significant shortcomings in handling complex scenarios requiring dynamic reasoning and procedural understanding.
AINeutralarXiv – CS AI · Mar 46/102
🧠Researchers introduce UniG2U-Bench, a comprehensive benchmark testing whether unified multimodal AI models that can generate content actually understand better than traditional vision-language models. The study of over 30 models reveals that unified models generally underperform their base counterparts, though they show improvements in spatial intelligence and visual reasoning tasks.