AIBullisharXiv – CS AI · May 276/10
🧠Researchers propose Mixture of Activations (MoA), a novel feedforward network design that dynamically selects activation functions per token rather than applying a single fixed function across all inputs. Theoretical analysis proves MoA offers strict expressivity advantages over fixed-activation networks, while empirical testing on language models up to 2B parameters demonstrates consistent improvements in loss metrics with minimal computational overhead.
AINeutralarXiv – CS AI · May 276/10
🧠Researchers introduce the s-Trace method to analyze how transformer-based LLMs utilize their computational capacity, revealing that model computation organizes into two distinct phases: a sparse early-layer core providing rough predictions, refined through denser later-layer computations. The findings suggest LLMs operate with modular efficiency rather than fully exploiting their parameter capacity across all inputs.
AIBullisharXiv – CS AI · May 276/10
🧠Hi-SAM is a new hierarchical multi-modal recommendation framework that improves how AI systems process diverse data types (text, images) for personalized suggestions. The system addresses tokenization inefficiencies and architectural misalignments in existing approaches, achieving 6.55% improvement in core metrics when deployed at scale.
AIBullisharXiv – CS AI · May 276/10
🧠Researchers have developed a transformer-based architecture for continuous sign language segmentation, using the BIO tagging scheme and HaMeR hand features combined with 3D angles. The method achieves state-of-the-art results on DGS Corpus and surpasses benchmarks on BSLCorpus, with significant implications for automated sign language translation and dataset annotation.
AIBullisharXiv – CS AI · May 126/10
🧠VECTOR-Drive introduces a tightly coupled vision-language-action framework for autonomous driving that balances semantic reasoning with motion planning through expert routing. Built on Qwen2.5-VL-3B, the system achieves 88.91 Driving Score on Bench2Drive by routing vision-language tokens to semantic experts while handling trajectory computation separately, demonstrating advances in multimodal AI for real-world driving tasks.
AINeutralarXiv – CS AI · May 126/10
🧠Researchers studying one-layer Transformers discovered that architectural choices in feedforward networks (FFNs)—particularly sparse mixture-of-experts (MoE) routing—fundamentally reshape how attention mechanisms learn to compute, with sparsity rather than learned specialization driving this computational redistribution.
AINeutralarXiv – CS AI · May 126/10
🧠Researchers introduce Mixture of Layers (MoL), a novel architecture that extends Mixture-of-Experts concepts from individual experts to entire transformer blocks, using parallel thin blocks with learned routing. The approach incorporates hybrid attention combining global softmax with linear attention to address token coverage limitations in sparse routing systems.
AINeutralarXiv – CS AI · May 116/10
🧠Researchers present the E∆-MHC-Geo Transformer, a novel deep learning architecture that maintains orthogonality in residual connections across all input values and parameters, outperforming existing methods like JPmHC and GPT on stability and rotation metrics while using 33% fewer layers.
AIBullisharXiv – CS AI · May 116/10
🧠Researchers introduce the Byte Latent Transformer (BLT), a new approach to byte-level language models that dramatically accelerates generation speed through diffusion-based and speculative decoding techniques. The methods reduce memory-bandwidth costs by over 50% compared to standard byte-level models, potentially making byte-level LMs practical for real-world deployment.
AINeutralarXiv – CS AI · May 116/10
🧠Researchers have successfully adapted Vision-Language Models (VLMs) based on LLaMA 3.2 to classify neutrino events in high-energy physics detector data, demonstrating that transformer-based architectures outperform traditional CNNs while offering superior interpretability. This work showcases the broader applicability of large multimodal AI models beyond natural language processing to specialized scientific domains.
AIBullisharXiv – CS AI · Apr 206/10
🧠Researchers introduce Transformer Neural Process - Kernel Regression (TNP-KR), a scalable machine learning architecture that dramatically reduces computational complexity for neural processes from O(n²) to O(n_c) while maintaining or exceeding accuracy. The breakthrough enables processing of 100K context points with 1M+ test points on a single GPU, advancing the feasibility of neural processes for large-scale applications.
AINeutralarXiv – CS AI · Apr 146/10
🧠Researchers introduce LIFESTATE-BENCH, a benchmark for evaluating lifelong learning capabilities in large language models through multi-turn interactions using narrative datasets like Hamlet. Testing shows nonparametric approaches significantly outperform parametric methods, but all models struggle with catastrophic forgetting over extended interactions, revealing fundamental limitations in LLM memory and consistency.
🧠 GPT-4🧠 Llama
AINeutralarXiv – CS AI · Apr 76/10
🧠Researchers conducted the first comprehensive analysis of emotion representations in small language models (100M-10B parameters), finding that these models do possess internal emotion vectors similar to larger frontier models. The study evaluated 9 models across 5 architectural families and discovered that emotion representations localize at middle transformer layers, with generation-based extraction methods proving superior to comprehension-based approaches.
🏢 Perplexity🧠 Llama
AINeutralarXiv – CS AI · Mar 266/10
🧠Research shows that newer LLMs have diminishing effectiveness for early-exit decoding techniques due to improved architectures that reduce layer redundancy. The study finds that dense transformers outperform Mixture-of-Experts models for early-exit, with larger models (20B+ parameters) and base pretrained models showing the highest early-exit potential.
AIBullishMarkTechPost · Mar 167/10
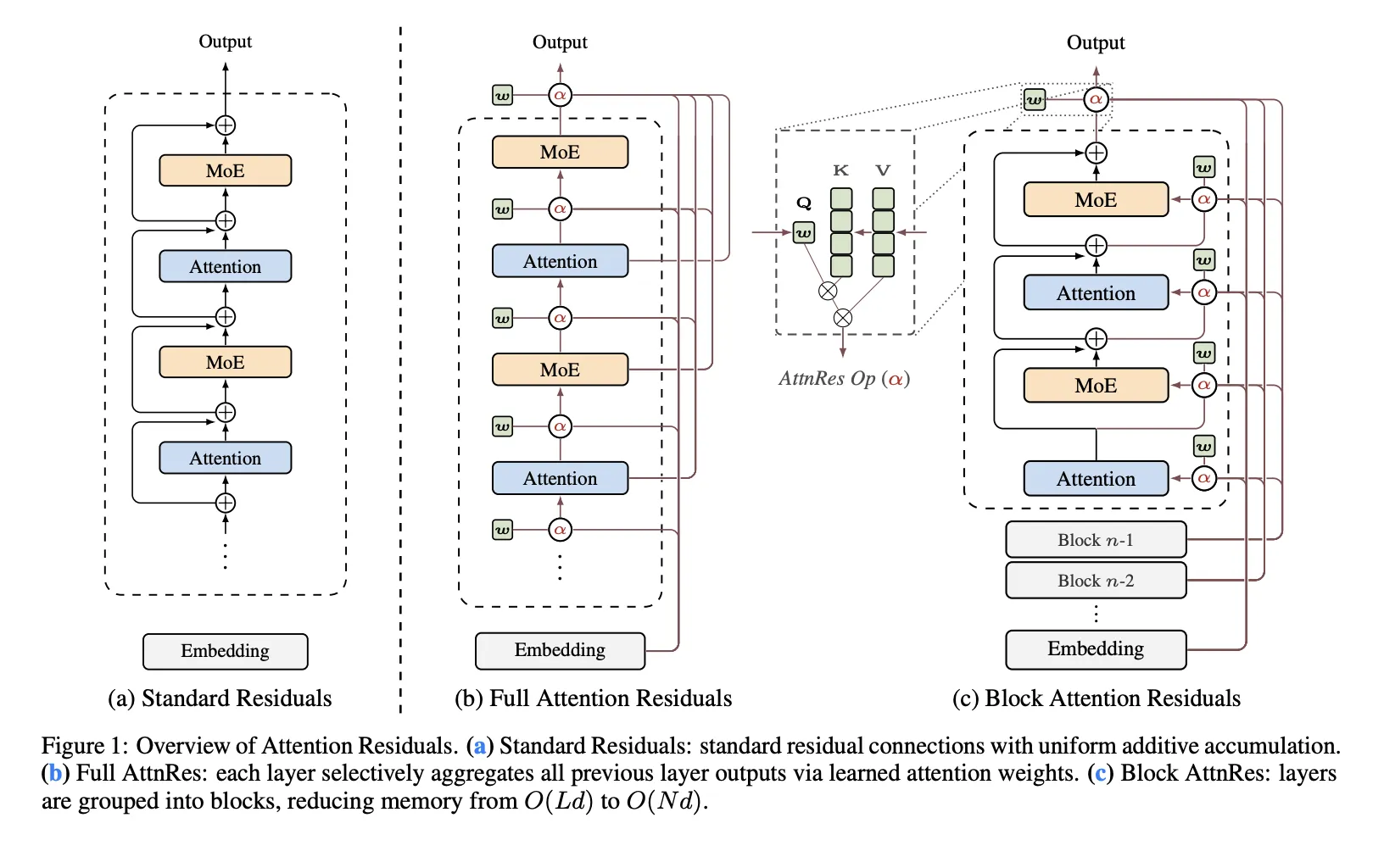
🧠Moonshot AI has released Attention Residuals, a new approach that replaces traditional fixed residual connections in Transformer architectures with depth-wise attention mechanisms. The innovation addresses structural problems in PreNorm architectures where all prior layer outputs are mixed equally, potentially improving model scaling capabilities.
AINeutralarXiv – CS AI · Mar 36/103
🧠Research paper analyzes test-time scaling in large language models, revealing that longer reasoning chains (CoTs) can reduce training data requirements but may harm performance if relevant skills aren't present in training data. The study provides theoretical framework showing that diverse, relevant, and challenging training tasks optimize test-time scaling performance.
AIBullisharXiv – CS AI · Mar 36/103
🧠Researchers have developed EDT-Former, an Entropy-guided Dynamic Token Transformer that improves how Large Language Models understand molecular graphs. The system achieves state-of-the-art results on molecular understanding benchmarks while being computationally efficient by avoiding costly LLM backbone fine-tuning.
AINeutralHugging Face Blog · Jan 201/103
🧠The article title references 'Differential Transformer V2' but contains no actual content or article body to analyze. Without substantive information, no meaningful analysis of developments, implications, or market impact can be provided.